Malwarebytes Anti-Malware 1.75 update adds archive scanning

Malwarebytes Anti-Malware is one of those programs that every Windows users should have installed on their system. I'm not saying that it should be the primary antivirus software on the system, especially since the free version does not support the real time scanning of objects and files, but that it should be installed as a second-opinion scanner to make sure nothing malicious slips by the resident antivirus program on the system.
The application supports the majority of features one would expect to be supported by an on-demand scanner. You can run a quick scan which checks the memory and critical locations on the system, or a full scan to scan every file and the memory instead.
The scanner ships with its - regularly updated- virus definition database and heuristics module to catch malicious software that has not been added yet to that database.
A recent update of Malwarebytes Anti-Malware to version 1.75 introduces a new feature to the application. Up until now, the program skipped files that were stored inside archives. The new update adds archive scanning to the application so that files stored inside archives are now also scanned by it automatically.
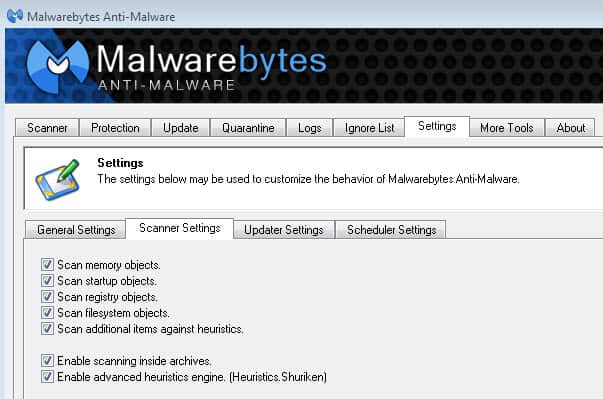
It should be obvious that this is only the case for archives that are not protected by a password or through other means. The program itself does not list the supported archive formats. According to official sources, it supports the scanning of rar, zip, 7z , cab and msi archives, as well as the scanning of the self extracting executable file formats 7z, zip, rar and nsis.
The scanning of archives may slow down the overall scan speed especially if large archives are stored on a storage device that is included in the scan. You can turn off the feature in the Settings under Scanner Settings > Enable scanning inside archives in this case or use the ignore list to add safe archives to that list so that they won't be scanned.
Malwarebytes Anti-Malware should inform you about the update next time you start it up. Just follow the updating procedure to install the new version on your system. You can alternatively download version 1.75 of the application from the official website.
Advertisement













It seems that it could scan password protected archives if you give it the password.
Does this new feature work in the “free version”..? Note: The “free version” IS NOT the “free trail version”.
It is most important update for that users who is mostly download file via online non-popular and file hosting sites, mostly hacker are put their virus and Mallware file in the archive file so we can download and extract that file in our PC. and our pc going to harmful. and this software is supports and scan popular archive extension like rar, zip, 7z , cab and msi.
Finally i download and install latest 1.75 free version from the official site .
Is it protected from decompression (zip) bombs?
I use MBAM free as such 2nd opinion scanner; when I updated it last night (its update screen auto-took me for it), the “new” version at PC startup tells me my protection is over and trial is expired; however, each time thereafter so far, MBAM itself opens as usual, updates, and scans…this is either a bug or some kind of sales pitch in the latest version. I mention in case others see it in theirs.