Panda Cloud Antivirus Free 3.0 review

Panda Cloud Antivirus is a popular security program for the Windows operating system by Panda Security. The antivirus application has just been updated to version 3.0, a major new version that ships with several new features.
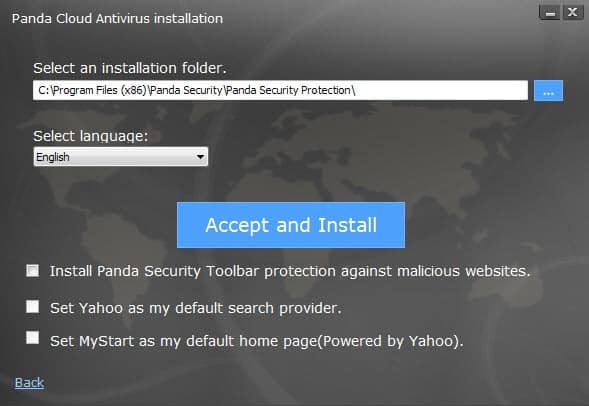
The software is provided as a net or stub installer which downloads the installation package from the Internet. The first thing you will notice -- or not -- when you run the installer is that it ships with third-party offers that are selected by default.
If you click next on the first screen without reading what is selected, you will end up with the Panda Security Toolbar in Internet Explorer and Firefox, Yahoo as the default search provide in Internet Explorer, Firefox and Chrome, and My Start as the default home page in Internet Explorer, Firefox and Chrome with web search powered by Yahoo.
If you do not want these modifications made to your system, uncheck the boxes on the installation options screen.
As far as new features are concerned, there are quite a few but not all of them are available in the free edition of Panda Cloud Antivirus.
The application features a new look which you may notice right away if you have updated to the new version from an existing one, or have seen screenshots of the old interface before.
The interface looks similar to Microsoft's Windows 8 interface. If you compare it to the previous interface, you will notice that it uses a wider layout that displays additional information and options right away.
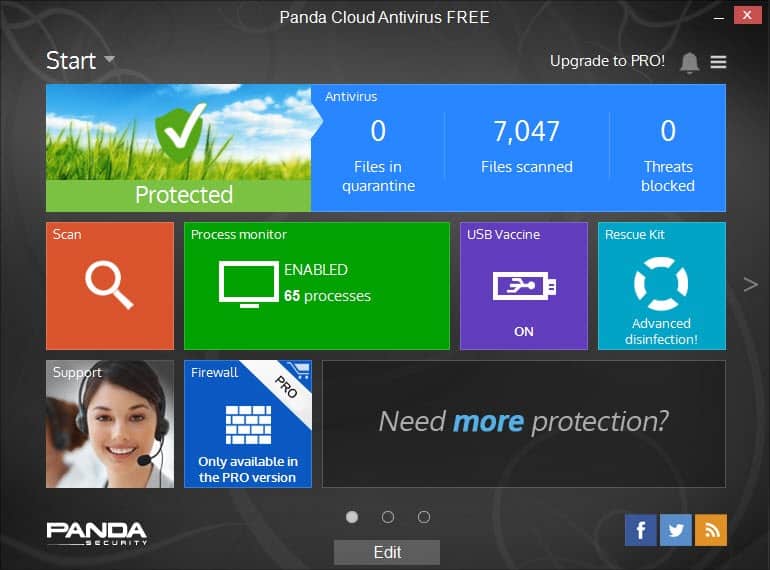
As far as new features are concerned, you find quite a few in the free version. The first that you may notice is that it is now possible to schedule scans of the system, something that was not possible before. The feature has been implemented in both the free and pro version of Panda Cloud Antivirus 3.0.
To schedule scans, click on the large rectangle in the top line and there on the add scheduled scan button. Here it is possible to select the frequency, day and time, scan range, and configure exclusions and advanced scanning options.
Another new feature is the built-in rescue kit option. Click on Rescue Kit in the main interface to create a new USB Flash Drive that you can boot from to scan the PC and remove malicious software that is detected during the scan.
USB vaccination is another new feature, at least in the free version. It was available in the pro version previously and has been integrated into the free version in version 3.0 of the application. It prevents autorun files from running when USB devices are connected to the PC, and offers to protect the autorun file on USB devices so that it cannot be used by malware anymore.
Panda has integrated an account feature into the application. According to the company, it allows users to use the technical support forum, manage services and download products from the company.
It does not seem to be required though to run the application, and you can skip the account registration entirely for now.
How good is Panda?
Panda Antivirus has received a very good rating in AV-Comparatives most recent Real-World Protection Test and AV-Tests most recent Windows 7 test.
It did not perform as good in AV-Comparatives file detection test where it landed in the middle of the test field.
Download
You can download the most recent version of Panda Cloud Antivirus 3.0 Free from the official company website. A full offline installer does not seem to be available right now.
Verdict
The new version improves Panda Cloud Antivirus Free in several key areas. Especially the option to schedule scans was missing from previous versions.
The program received several solid ratings in recent antivirus tests, and while you should not base your decision solely on those, it is reassuring nevertheless.
















The scheduled scans do not work in the free version.
Panda is not a bad product… they just dont have much visibility.
Parental Control and Data Shield
Because of removal of these, I will now be using a different anti-virus.
I like the interface of this new version of Panda Cloud Antivirus 3.0. It is now more user friendly, however the removal of Parental Control and Data Shield is what I care about. These two feature, for me, are very useful. Nevertheless, overall, the new version is still better but keeping those features will make it the best free Antivirus instead.
Downloaded and installed version 3.0, replacing 2.3. Within 24 hours was infected with coinminer trojan. Unable to remove with Superantispyware pro (said it removed it, but keeps finding it again) or with Malawarebytes operating in safe mode (Panda, F-secure, and BitDefender of no use either).
So have restored to week old backup image and to version 2.3. For what it might also be worth, I keep the ‘safe boot’ option off in windows 8.1 so I can boot from repair USB if I need to. Perhaps safe boot might have been a protection, I am not techie enough to know.
Here is Offline Installer:
http://acs.pandasoftware.com/cloudantivirus/v3/173653/CloudAntivirus.exe
Thanks!
@leon.
Relax. Do not worry regarding the New version update.
This is what the Panda Cloud Antivirus Blog has to say on the matter:
If you are reading this post after seeing a “Panda Cloud Antivirus has upgraded automatically!†message in your system tray, then you already have the latest version installed and running, and you don’t have to do anything else. If your version of Panda Cloud Antivirus hasn’t upgraded to version 3.0 yet, don’t worry: your copy of Panda Cloud Antivirus will upgrade itself automatically in the next few days.
We’d like to thank all of our users once again for helping us develop this great Panda Cloud Antivirus.
Enjoy the new version 3.0!
Hope this helps,
i
ah i see, thanks for the info :)
The removed the best feature “DATA SHIELD” which (in theory at least) offered protection against crypto ransomware.
Overall not a bad program (good detection, light on resources, no major bugs).
The bad : support for free version is almost non -existent, have to install a toolbar.
Download for now works from here.
http://blog.cloudantivirus.com/?_ga=1.218099536.734016557.1399583025
i cant find version 3, i keep getting version 2.3