Web LLM brings browser-based revolution to AI

A team of developers is working to bring language model chats directly to web browsers, operating entirely in-browser with WebGPU acceleration. The project acknowledges advancements in generative AI and language model development, thanks to open-source contributions like LLaMA, Alpaca, Vicuna, and Dolly. The goal is to create open-source language models and personal AI assistants integrated into web browsers, harnessing client-side computing power.
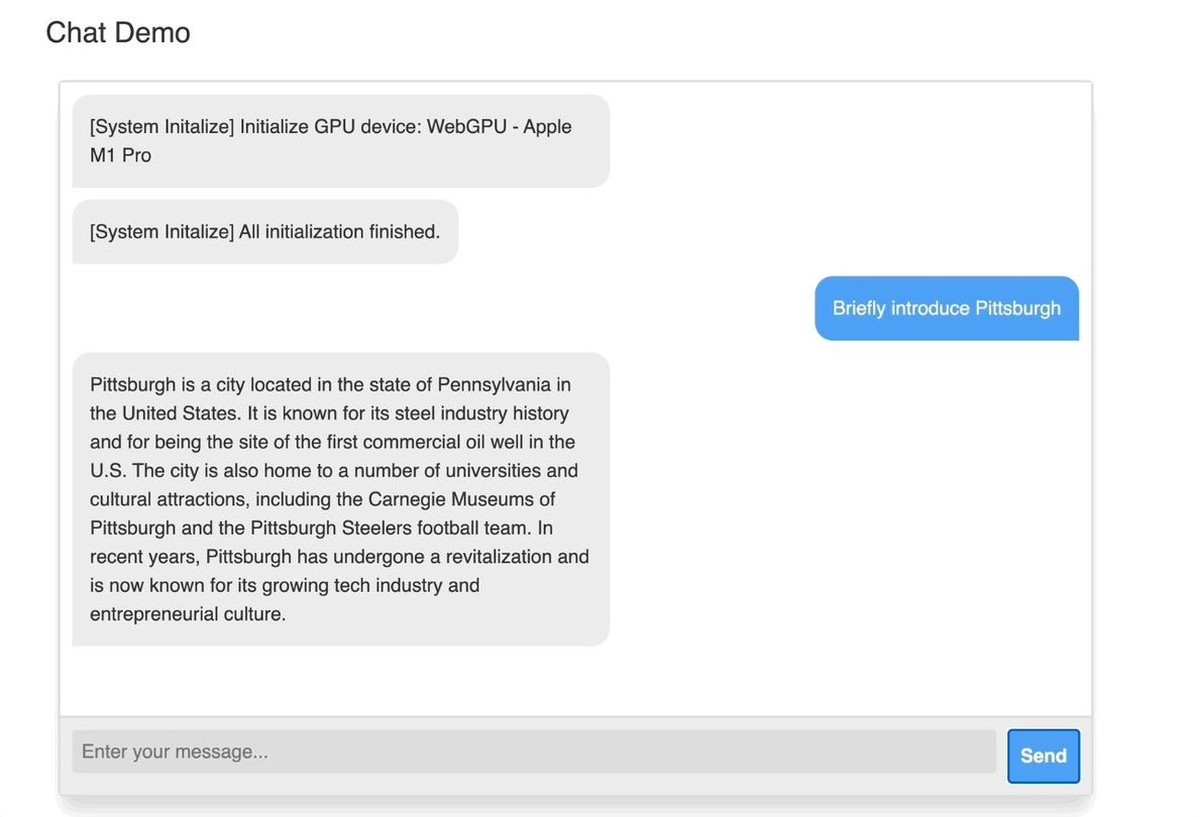
Web LLM is a groundbreaking innovation in AI and web development, enabling fine-tuned models to run natively within browser tabs without server support. This local processing addresses privacy and security concerns, giving users control over personal information and reducing the risk of data leaks, especially concerning Chrome extensions or web applications.
The creator has opened a demo site for the Web LLM, but at the time of writing the demo is down.
Overcoming challenges and optimizations
Significant challenges include the need for GPU-accelerated Python frameworks in client-side environments and optimizing memory usage and weight compression for large language models. The project aims to develop a workflow for efficient language model development and optimization using a Python-first approach and universal deployment.
The project employs machine learning compilation (MLC) with Apache TVM Unity, utilizing native dynamic shape support to optimize the language model's IRModule without padding. TensorIR programs are transformed and optimized for deployment across various environments, including JavaScript for web deployment.
Utilizing int4 quantization techniques, the project compresses model weights and employs static memory planning optimizations to reuse memory across multiple layers. A wasm port of the SentencePiece tokenizer is used, with all optimizations executed in Python, except for the JavaScript application connecting components.
The role of open-source ecosystems
The open-source ecosystem, specifically TVM Unity, facilitates a Python-centric development experience for optimizing and deploying language models on the web. TVM Unity's dynamic shape support addresses the dynamic nature of language models without padding, and tensor expressions enable partial-tensor computations.
You may check out the project's GitHub page via the link here.
Comparing WebGPU and native GPU runtimes reveals performance limitations due to Chrome's WebGPU implementation. Workarounds like special flags can enhance execution speed, and forthcoming features such as fp16 extensions exhibit potential for substantial improvements.
How to install Web LLM to Chrome?
WebGPU recently debuted in Chrome and is now in beta. They currently conduct their experiments in Chrome Canary, and you can also try the latest Chrome 113. Chrome version ? 112 isn't supported and using it will result in an error related to WebGPU device initialization and limits. The tests were performed on Windows and Mac, requiring a GPU with approximately 6.4GB of memory, say the creators.
For Mac users with Apple devices, follow these instructions to run the chatbot demo locally in your browser:
- Install Chrome Canary, a developer version of Chrome that enables WebGPU usage
- Launch Chrome Canary. We recommend launching it from the terminal with this command (or replace Chrome Canary with Chrome):
/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary --enable-dawn-features=disable_robustness - This command disables the robustness check in Chrome Canary that slows down image generation. While not mandatory, we strongly advise using this command to start Chrome
Enter your inputs and click "Send" to begin. The chatbot will first fetch model parameters into the local cache. The initial download may take a few minutes, but subsequent refreshes and runs will be faster.
Advertisement

















We should also integrate an option for distributed computing, like folding@home, dedicating a certain percentage of cpu/gpu power as a decentralized service. Decentralized supercomputing would significantly aid with computationally intensive AI tasks and or building language models.
They should also integrate an option for distributed computing, like folding@home, dedicating a certain percentage of cpu/gpu power for a decentralized service, as decentralized supercomputing would significantly aid with CPU intensive tasks.