How to repair and extract broken RAR archives

Broken, damaged or corrupt archives can be quite annoying. It does not really matter if an archive that you have created locally is not working anymore, or if you have downloaded Megabytes or even Gigabytes of data from the Internet only to realize that one or multiple of the files of the archive are either damaged or missing completely.
That does not mean that the data cannot be repaired or extracted anymore. Depending on the circumstances, you may be able to recover the archive fully, or at least partially.
When you try to extract a broken RAR archive, you will receive a prompt requesting that you select the next file in line manually from the local system, or receive the error "CRC failed in file name" in the end.
This is a dead giveaway that a volume is missing or damaged, and that some of the extracted files may be corrupt or even non-present as a consequence.
When you receive that message, you have a couple of options to proceed.
1. Recovery Records
When you create a new archive using WinRAR, you can add so called recovery records to it. To do so, you simply check the "Add Recovery Record" box when the archive name and parameters dialog appears.
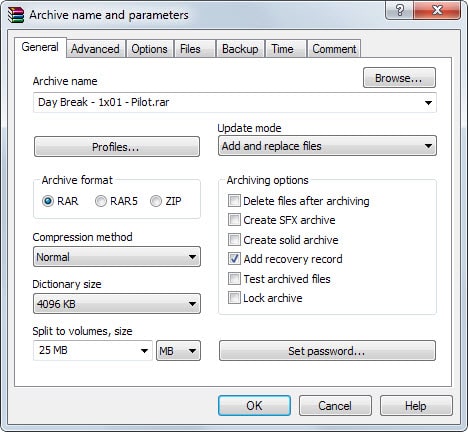
You can only do so if you are creating a multi-file RAR or RAR5 archive, and not when you use ZIP as the archive format or want to create a single file only.
The recovery information increases the archives size by 3% by default. This means basically that you will be able to restore up to 3% of missing or damaged data by default.
You can switch to the advanced tab to modify the percentage to either increase or decrease it.
The recovery record is added to the directory the archive is created in. Each file begins with rebuilt so that you always know that this is a recovery file and not part of the original archive.
To recovery the RAR file, you open it in WinRAR, right-click all archives, and select the repair option from the menu. WinRAR will pick up the recovery volume or volumes automatically and use them to repair the archive and add the fixed files to the system.
2. PAR Files
So called Parity files offer a second option. They are often used on Usenet, but come in handy for backups and in all other situations where you need to move large archives to another location.
What makes PAR files great is the fact that you can repair any part of an archive using them. As long as they are at least equal in size to the damaged part, they can be used to repair the archive.
If you have never heard about PAR or PAR2 files before, check out my guide that explains what they do and how you can use them.
You may need to use software to make use of PAR files. Some Usenet clients ship with their own implementation, so that it is not necessary in this case to install a different program to handle the files.
My favorite Usenet client Newsbin for instance supports parity files for example and will download them intelligently whenever they are present and required to extract archives (which it can also extract automatically).
Standalone programs that you may want to consider using are MultiPar or QuickPar.
3. Extract the archive partially
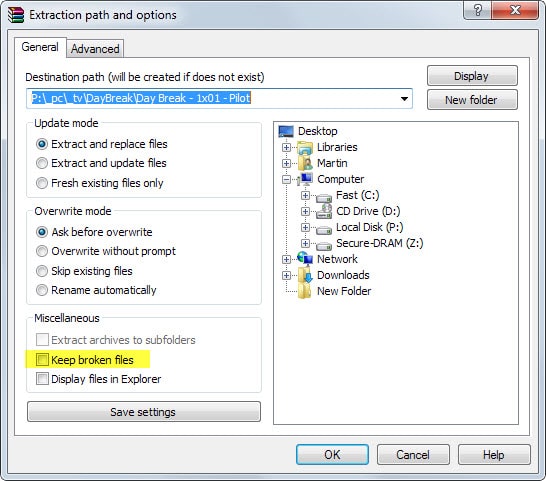
If you don't have access to recovery volumes or parity files, you may still extract the archive partially to your system. This works best if the archive is damaged at the end as you can extract all contents up that point in this case.
You need to enable the "Keep broken files" option on the extraction path and options prompt to do so. If you don't, WinRAR won't keep partially extracted file contents on the disk.
4. Redownload
Last but not least, re-downloading missing or corrupt files may also resolve the issue. This works best if you have downloaded the files faster than they were uploaded for example, or when the original uploader noticed that files were corrupt and uploaded new copies which you can then download to your system to complete the archive.
You may also ask for others to fill the missing or corrupt files, or seek out another destination to get the full copy. On the Usenet, it is sometimes the case that files are corrupt when you are using one provider, but not corrupt when you switch the provider.
That's why some users use so called fillers, secondary Usenet providers that are used whenever the primary provider fails to provide access to a file.
Have another option? Add it as a comment below and share it with everyone.
Now Read: How to pick the right Usenet Provider


















To be honest, my file is corrupted or something it’s a Cleo for GTA III and when I download it, it either fails or when it actually downloads instead of failing it doesn’t appear on the desktop, or when I have the WinRAR open it automatically disappears I tried 7-zip didn’t work either.
GOD BLESS YOU! Better than other scamming websites.
I ticked “keep broken files” and it worked. Thank you so much.
Hi Martin, I have this file in a pendrive, which while saving I password protected through WINRAR. Now when am trying to access it, getting these error messages
1) when am trying – right click > open with WINRAR | Error Message directly says – Cannot Open filepath
2) when am trying – right click > extract here/files/to same folder (through WinRAR) | Two windows of error messages appear a) WinRAR Diagnostic Message says – Cannot open filepath, Access is denied and other error message b) Warning! – No archive Found
3) when am trying – right click > open with WINZIP | Error Message says – Could not open filepath, probable cause: file sharing and file permission problem.
To fix file sharing / permission, have tried all that is required to try giving it Admin access with full permission. But still gives the same error. Not even able to copy this rar file to desktop from pendrive
4) when am trying to open with RAR Opener, am not even getting any error message but an ad.
Can you please help fixing/recovering the files, its super important for me.
Thanks a ton in advance!
Just recently my firefox has been struggling to finish most rar file downloads (getting all but 1% then eventually registering as fail). I’ve noticed if you copy the rar.part file once it has got to the 1% left stage, paste it elsewhere, rename as .rar and unwrap, nine times out of ten you can salvage most if not all the contents. whereas leave it to hopefully finish and it generally times out as a fail and is gone.
use a dedicated download manager, and stop using an internet browser to download, upload files.