CrowdInspect gives your running processes a thorough malware inspection

Malware needs to run on a system to be effective, which is why you will find many malicious software running as a process when you open the Task Manager.
The main issue here for many users is that it is not often that easy to distinguish between legitimate programs and malware, as process names do not necessarily tell you anything about legitimacy.
While it is possible to spot new processes or suspicious ones, it is up to you to follow up on that and have the suspicious ones scanned by antivirus software.
CrowdInspect is a free cloud-based scanner for the Microsoft Windows operating system that goes a step further than most programs of its kind.
Unlike programs such as Process Explorer or HerdProtect, which scan all running processes using Google's VirusTotal service, CrowdInspect uses APIs from several services to retrieve additional information.
The program will scan the processes using VirusTotal's scan engine, but also request Web of Trust information about any domain name or IP address that is open, and against Team Cymru's malware hash database.
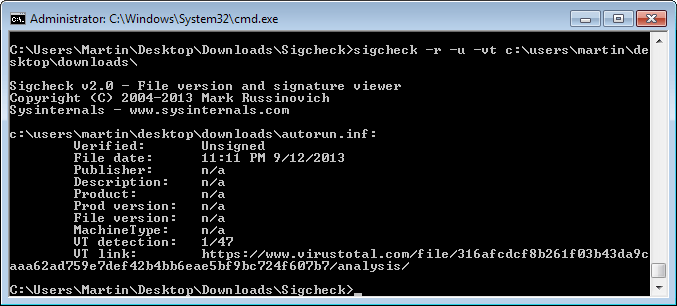
When you first start the application you will see a list of all running processes. Next to standard information such as the process name and ID, you find columns that highlight whether the process has already been scanned or not.
Gray circles indicate that it has not been scanned yet, while green or red circles indicate it has been. Green means that everything is in order, while red means a potential malware hit.
The Web of Trust score in addition to that is displayed in percentage.
Next to that are information about local IPs and ports, as well as remote IPs and ports, and DNS information.
You can right-click on any line in the program to display a list of actions that include killing the process or closing its connection to a network or the Internet.
Here you can also display the VirusTotal results -- it appears to display only some engine results and not all 40+ of them -- or copy information to the Windows Clipboard.
You can switch from the program's live view to the history view using the toggle button in the main toolbar. This displays chronological information about each process the program detected while it was running.
Note that the information displayed here are pruned when you close the application, so make sure you copy them before you do so if you need them at a later point in time.
The program runs continuously until you hit the pause button in the interface or close it.
Criticism
CrowdInspect uses various security APIs to detect potentially unwanted programs and addresses on your system. What it does not do is give you the tools at hand to remove those from your system.
While it is easy enough to close a browser tab to close the connection to a site that WOT does not rate highly, the actions to deal with malicious processes runs short. You can kill the process, but if the malware is any good, it will either prevent that from happening, or appear again at a later point in time.
What this means is that you need another program for the cleaning. Malwarebytes Anti-Malware for example.
Verdict
CrowdInspect is a second-opinion scanner that you can use to quickly scan all running processes and addresses that they are connected to for malicious intent.
It does a solid job at that and since it is a portable application, does not get in your way. It may make sense to run it from time to time on your system to make sure everything is in working order.
Now Read: Boost your security with Sandboxie
Advertisement














Mr. Brinkmann:
Hi.
. . . and speaking of scanning processes Mr. Brinkmann please do a review of this WONDERFUL piece of software called Free Fixer that I use and recommend. It is the brainchild of a Mr. Roger of whom I have been in correspondence.
Once I used it to locate a super Trojan that kept C-r-a-s-h-i-n-g my computer!
It was hidden in a folder that FF had located in my “C” drive.
After I located it (the second time), I destroyed the key folder plus terminated its sub folders (which is Very Important to do!)
At first, I learned this the hard way when I thought I destroyed this Trojan only for it return in another guise!
But once I destroyed BOTH its core and it’s deadly sub folders my computer’s operation returned to normal Without crashing this time.
I was so grateful for FF for what it had done for me – – saved me from a re-installation of windows – – that I purchased the paid version of FF (as a donation).
I can only recommend FF for those of us who are a bit computer savvy and would know which bad file to delete!
(the FF website does give you some information about a questionable file you have; if it was scanned by VirusTotal and the results and what others feel about a particular file).
Mr. Roger is an amiable man who does respond to all e-mail inquiries regarding his product.
Free Fixer can be found at http://www.freefixer.com
TR
Thanks.
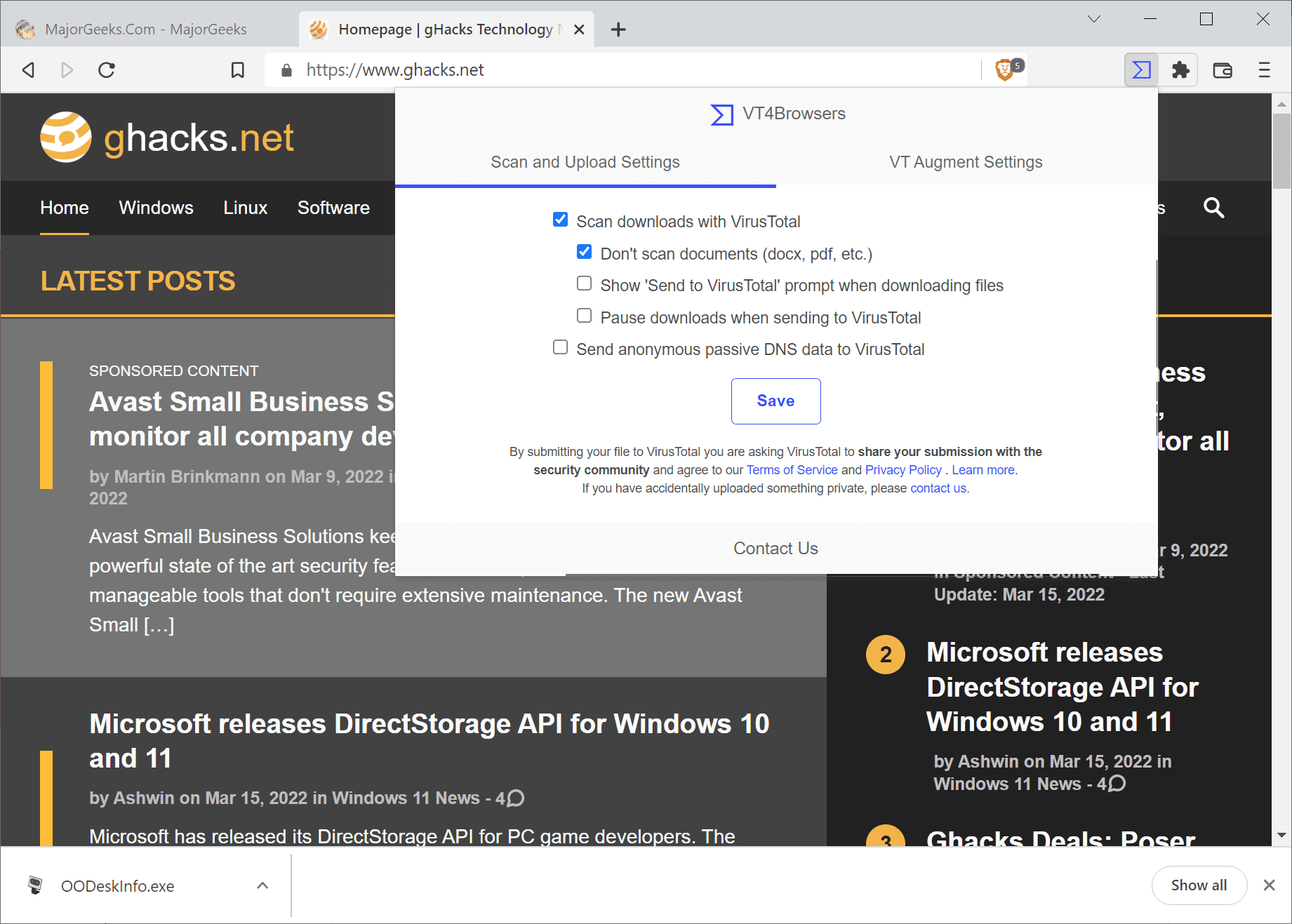
Man, Process Explorer sends a list of your running process to Google now?
So far as CrowdInspect is concerned, there’s something ironic about an anti-spyware tool sending your data to the world’s largest spyware company.
Only if you enable the feature.