Digg Reader now allows data export

In the wake of the closing of Google Reader at the start of this month, many services beefed up for the onslaught of business, while other new ones suddenly sprung to life. One of those came from Digg, the social sharing site started by Kevin Rose, which has lost some of its prominence in recent times.
The company has, so far, done a credible job designing its entry into the RSS market, but also seems to be taking user comments and requests seriously. Like Feedly found out, customers wish to have an out -- a way to remove data from the service in the event they choose to move on. Feedly finally caved and included OPML export and now Digg has done the same. Google, to its credit, has always made this process simple.
"We’re sprinting hard to knock off as many feature requests as possible, as quickly as possible. Today we’re happy to announce that you can now export your subscriptions from Digg Reader".
To get started, head to Digg Reader and look for the Settings  under the gear icon on the top right. Scroll down towards the bottom and find the heading for Reader, which contains a number of valuable settings.
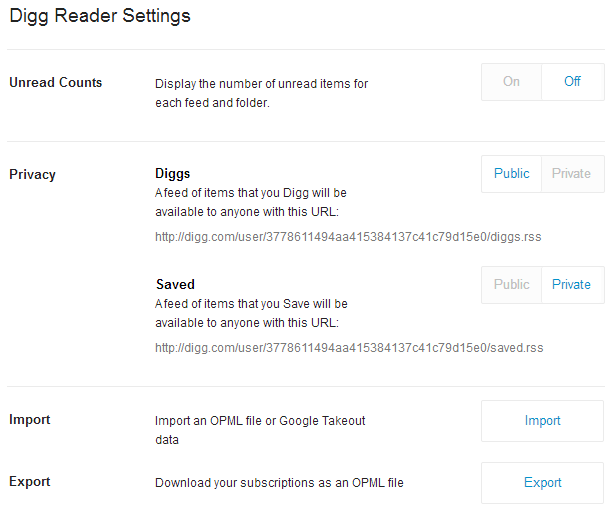
At the very bottom of this you will find a brand option called, quite unoriginally, Export -- hey, it gets the point across and that is the goal here.
From here it is only a matter of clicking the blue "export" link and you are on your way to receiving your data file and will be ready to move along to any of the numerous competitors.
Conclusion
As I previously stated, there are numerous replacements for Google Reader on the market, and Digg is only only one in this crowded field. Exportation of your data is a key to making users happy and was one of my biggest gripes about Feedly -- okay, there were several, but that was one of the largest. Digg's addition of the feature makes it much more palpable as an alternative.
Personally, I prefer to have my feeds stored in at least two services in case one experiences issues, as I need up-to-date news for my job.
Advertisement
















Hi Guys,
If what you want is the ability to skim large #s of headlines, organize lots of feeds, label them, tag articles for later reading in one fast unobtrusive “no magazine layout” reader, SwarmIQ is your choice.
Sign up at http://www.swarmiq.com/register/GOOGLEREADERISDEAD , click on the Google reader icon to get all your feeds, and get up and running straight away.
Disclosure: I’m on the team that built this site :-) Also, we don’t have “Google Alerts” type functionality yet.