How to use Google MusicLM?

Google MusicLM is an advanced language model specifically designed to produce musical compositions based on textual descriptions. This innovative model, developed by Google, focuses exclusively on the realm of music generation. Leveraging the foundation of AudioLM, which was primarily developed to deliver coherent speech and piano music continuations, MusicLM operates without the need for transcripts or symbolic music representations.
AudioLM's functionality involved converting input audio into a series of discrete tokens, enabling the model to learn patterns and structures inherent in the audio data. By utilizing this approach, AudioLM successfully generated audio sequences while maintaining long-term consistency.
Building upon this framework, Google MusicLM employs a similar methodology to generate music based on provided text descriptions. For instance, by inputting a descriptive prompt like "a soothing guitar melody in a 4/4 time signature riff," MusicLM can produce a corresponding musical composition that captures the essence of the given description. AudioLM comes with two tokenizers:
- SoundStream tokenizer which produces acoustic tokens
- w2v-BERT tokenizer which produces semantic tokens
Let's examine the hierarchical stages within AudioLM:
- Semantic modeling: This initial stage focuses on establishing long-term structural coherence. It involves extracting the high-level structure from the input signal, capturing the overall organization and arrangement.
- Coarse acoustic modeling: In this stage, acoustic tokens are generated, which are then concatenated or conditioned based on the semantic tokens. This process helps establish a coarse representation of the audio, considering both its semantic and acoustic aspects.
- Fine acoustic modeling: The third stage enhances the audio further by processing the coarse acoustic tokens alongside fine acoustic tokens. This additional refinement adds depth and intricacy to the generated audio. To reconstruct the audio waveform, the acoustic tokens are fed into the SoundStream decoder.
For MusicLM, the multi-stage autoregressive modeling of AudioLM serves as the generative component. However, MusicLM extends this capability by incorporating text conditioning. In the provided image, the audio file undergoes processing through three components: SoundStream, w2v-BERT, and MuLan. SoundStream and w2v-BERT, as discussed earlier, process and tokenize the input audio signal. On the other hand, MuLan represents a joint embedding model for music and text. It consists of two separate embedding towers, each dedicated to a specific modality, namely text and audio.
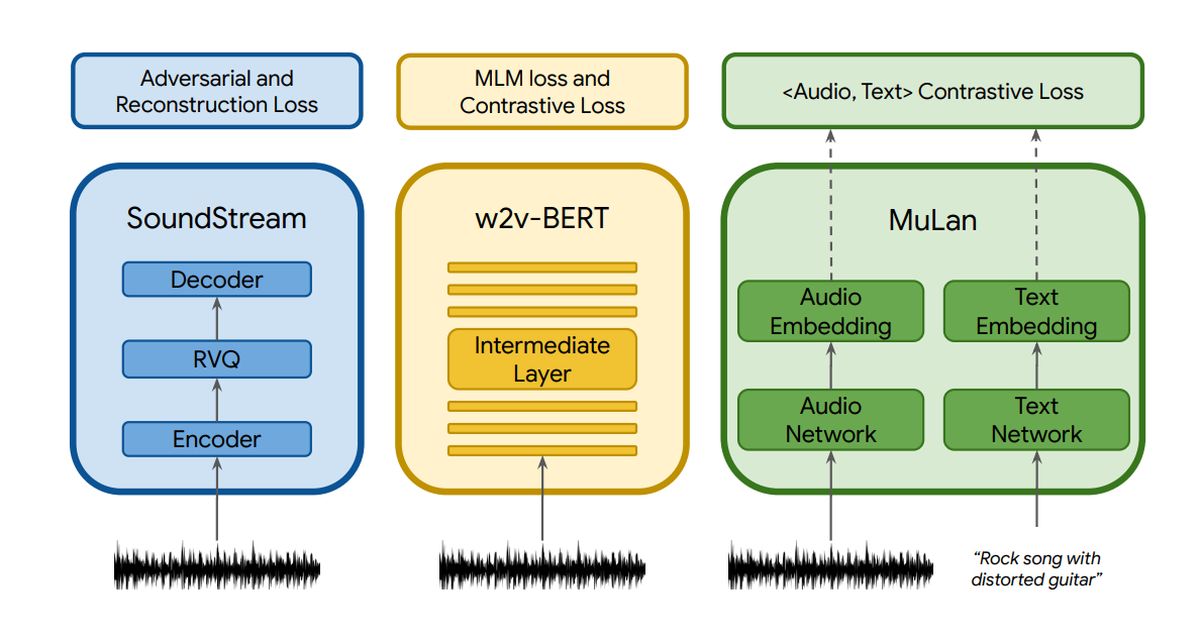
In the overall process, the audio is fed into all three components, while the text description specifically goes to MuLan. To ensure consistent representation, the MuLan embeddings are quantized, resulting in a unified format using discrete tokens for both the conditioning signal (text description) and the audio input.
The output generated by MuLan is then directed to the semantic modeling stage, where the model learns the relationship between the audio tokens and the semantic tokens. The subsequent steps follow a similar workflow as in AudioLM. To gain a clearer understanding of this process, please refer to the provided image.
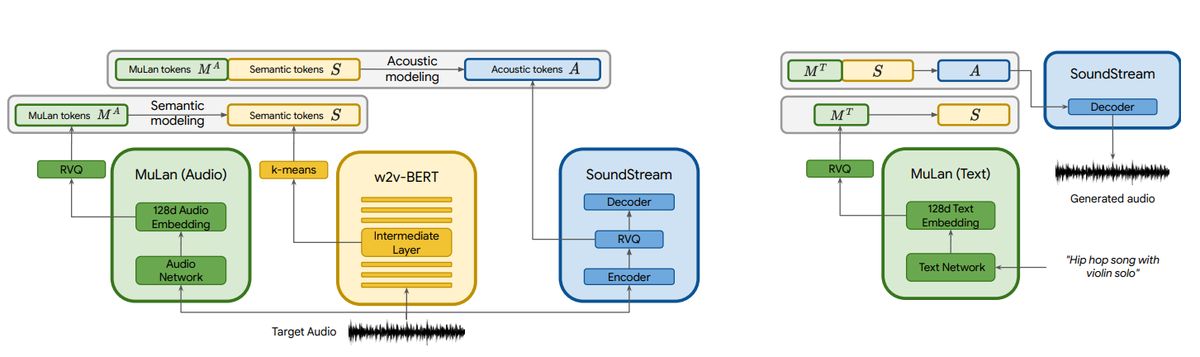
Advantages of MusicLM
MusicLM, being developed on the foundation of AudioLM and MuLan, offers three distinct advantages. Firstly, it possesses the capability to generate music based on text descriptions, allowing users to specify their desired musical composition in written form. Secondly, it can utilize input melodies to expand its functionality. For example, by providing a humming melody and instructing MusicLM to convert it into a guitar riff, it can successfully accomplish the task. Lastly, MusicLM excels at generating extended sequences of various musical instruments, enabling it to produce lengthy and intricate musical compositions across a wide range of instruments.
The training data used to train MusicLM consists of approximately 5.5k pairs of music and corresponding text. This dataset encompasses an extensive collection of over 200,000 hours of music, accompanied by detailed and descriptive text provided by human experts. Google has made this dataset available on Kaggle under the name "MusicCaps," and it can be accessed using this link.
Can I try it now?
Google has currently indicated that they do not have intentions to distribute the models associated with MusicLM. This decision may stem from the requirement for further development and refinement before the models can be made publicly available. However, in the white paper published by Google, numerous examples are provided to showcase the capabilities of MusicLM in generating music based on text descriptions. These examples serve to demonstrate the potential of the model and its ability to create music compositions guided by textual prompts.
Prompt examples
- Evocative descriptions: For instance, "An exhilarating soundtrack for an action-packed video game. It features a fast tempo, energetic beats, and an infectious electric guitar melody. The music is characterized by repetitive patterns that are both memorable and punctuated with unexpected elements like crashing cymbals and dynamic drum rolls."
- Extended duration: This remarkable functionality allows MusicLM to generate continuous, high-quality audio that spans 5 minutes. Users can provide text prompts such as "Sad post-rock" or "Funny hip-hop" to guide the generation of music, resulting in a cohesive and immersive musical experience.
- Narrative mode: This notable feature of MusicLM enables users to instruct the model to create a musical sequence by providing a series of text prompts that form a cohesive story. For example, "Begin with a soothing meditation (0:00-0:15), gradually transition to an uplifting wake-up theme (0:15-0:30), shift to an energetic running rhythm (0:30-0:45), and culminate in a motivational and powerful section (0:45-0:60)."
- Melody and text conditioning: Users can leverage this feature to generate music that aligns with a provided melody, whether it's a hum or a whistle, while still adhering to the desired text prompt. Essentially, it allows for the conversion of an existing audio sequence into the desired audio representation.
- Location-based themes: MusicLM can generate music based on descriptions of specific places or environments. For example, "Capture the serene and sun-soaked ambiance of a peaceful day by the beach" can serve as a text prompt to generate music that encapsulates the mood and atmosphere of such a setting.















Excellent article thank you!!
You didn’t get the memo about the idiotic use of question marks, did you?