uBlock's all and third-party deny modes block requests by default

Most content blockers use lists to determine what should be blocked and what should be loaded when a user makes a request.
Options to add custom filters are provided by many blocker extensions. If you are using the popular uBlock extension for example, you know that you can load and unload various network lists but also add your own custom rules that the extension follows to the letter.
The most recent development version of uBlock improves the extension's default deny blocking options by adding two new request types, all and third-party, to its list of options.
These options enable you to block (or allow) all requests of the selected type but with options to override the selection on a per-site basis.
The following default blocking options are provided, the two new types are highlighted.
- All - This works similar to how NoScript operates: don't allow anything to be loaded by default without user permission.
- Images - Allow or deny the loading of images.
- 3rd-party - This blocks third-party requests by default.
- inline, 1st-party or 3rd-party scripts - These three options block scripts that are loaded inline, from the same resource you are connected to or from third-party sites.
- 3rd-party frames - Blocks frames from third-party sites.
Setting it up
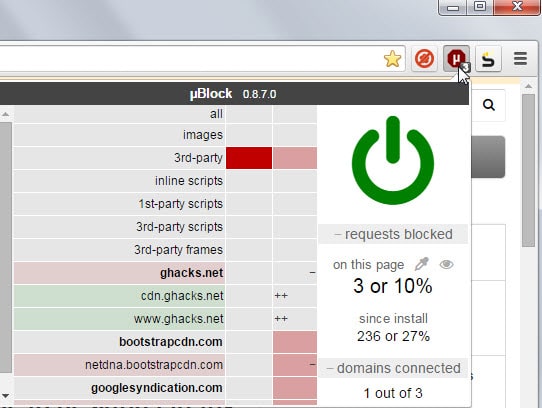
The option to block 3rd-party requests and all requests has been added in the most recent development version.
You only get to those options after checking the advanced user setting in the options. Once you have checked the option, click on the uBlock icon and then on requests blocked to display the filtering options.
There you find general blocking options at the top and below that the list of domains requests. The status of each requests is highlighted as well and you can override it easily here if the need arises.
To disable third-party requests click on the red part next to 3rd-party by moving the mouse there. Once done, all third-party requests are blocked by default.
You can override the selection on a per-domain basis and may need to do so on sites that use these requests for part of their core functionality.
Some sites may use other domains to load contents from. Google for instance uses loads data from gstatic.com and googleusercontent.com when you connect to its properties. While some work fine without allowing those, others may block contents from working correctly.
The benefits of blocking third-party requests range from faster page loading times to improved privacy and better resource usage.
The only negative issue that may arise is that some websites may not work properly anymore once you enable it. This happens if they require contents from third-party sites to function. You can fix that easily though by enabling those requests individually.
While that means additional work, it ensures that requests are only made if they are required for the site's functionality.


















Ubklock is nice but the control of it and the inability to easily see whats on a list fustrates me to no end.
Tried on palemoon, settings are accessible and so is context menu but no icon visible :(
This addon seems pretty decent though. : )
The difference between AdBlock and uBlock is the same as a CRT TV and a LCD TV, period.
Thank you gorhill.
uBlock seems to do a more versatile job than abp, with user-friendly neat visuals… if one sets the option as explained by Martin.
Options open also by dragging popup box away from its anchor…
A knee way, I can’t really tell about it’s memory footprint on a SSD system flushed with RAM and hooked to a very fast uVerse…
I agree with Alex’ comment about the missing “disable for ALL”.
Funny, though, what did I do to NOT see the green big button, only a green rectangle… the tiny icons show a placeholder…?
Besides that the functionality is there.
Thx again Martin.
uBlock has the ability to whitelist everything by default (aka global turn off), through dynamic filtering pane..
https://github.com/gorhill/uBlock/wiki/Dynamic-filtering:-turn-off-%C2%B5Block-everywhere
never mind the missing “icon(s)”… there were/are downloadable fonts … I had elected to not allow sites to use their own in FF > Tools > Options > Content : Fonts & Colors > Advanced > Allow pages to choose their own fonts….
Surf’s up with uBlock green button !
Been using uBlock for a few days now many thanks gorhill for your time and effort, and all the others at github. In Firefox i use the Hide Tab Bar With One Tab extension as i do not like the australis interface and it’s permanent tab, however there seems to be a problem, if i click on the uBlock icon then on the black version bar in the popup menu to go to uBlock dashboard which opens in it’s own tab then close dashboard tab the icon for Ublock now becomes, totally none functional and has a oblong light shaded area around it, this only happens if there are no other tabs which is how hide tabs addon functions, ie uBlock seems to need tabs or it’s icon locks up! other than that uBlock has made me a very happy bunny Thanks.
Have been using ublock (0.8.6.0) for a few days and am pleased with the memory usage – the new version sounds like a welcome improvement.
However, one big drawback for me is there seems to be no option to quickly disable it for ALL websites (like ABP offered) – have to display a site first then turn it off for that site then reload the page…
Does anyone know how to disable it across all sites (without having to disable the addon in the extensions menu?
Answer here: https://github.com/gorhill/uBlock/issues/40#issuecomment-73415681
> It’s a matter of toggling global setting of all to allow (green) in the dynamic filtering pane.
Thank you very much, I’ve upgraded to 0.8.7.0 and that toggling of All does the job perfectly :-)
And thanks for your effort in creating the addon itself – excellent replacement for ABP
some of these issues could also be attributed to the fact that I am using Cyberfox though. :/
uBlock for firefox just does not seem to do it for me.
– Accessing the ‘3rd-Party Filter Tab’ just causes it to hang
– The settings window cannot be resized
– The ‘Settings’ tab seems to fail to remember settings.
– A seemingly inability to access the settings (however limited they appear to be) from the icon itself without having to go through the addons panel and selecting ‘options’
Maybe by the time they reach their milestone version 1.0.0.0 they’ll have it all sorted but thus far it is not a replacement for adblock plus.
Its too bad Admuncher stagnated and fell behind because it was actually pretty decent back in the day.
> Maybe by the time they reach their milestone version 1.0.0.0
Version is just a label, “1.0” really means nothing. I just increment the version/revision count depending of what is new. As of now, I consider uBlock a fully developed piece of software. All software have issues, including those past the label “1.0”, as witnessed by their pile of issues in whatever bug tracking tool they use. uBlock is no worst than any of these, and I can make the case it has less issues oftencase.
No offense intended Gorhill, I actually think what you are doing is great and you seem like a really great guy (more of a community based person if that makes sense) I agree a version number changes nothing but time does and as such I am sure it will have matured 10 fold by the time it reaches the magic number (sorry I couldn’t resist that one). Its a shame it does not work with Cyberfox right now (not sure what the issue is, it may well be a conflict of addons too) but I will try it on Palemoon and see as I am sure I am missing out on a really brilliant addon.
I like the fact that it comes with an element picker tool straight of the bat, something that the folks at admuncher never provided so elegantly much to my disappointment.
I’m so eager I am going to fire up Palemoon right now and give it a shot.
I’ll have to admit it will be hard to tear away from abp but the fact that I am looking at this addon is saying a lot. ;-)
Thanks for the fine work and response.
Edit:
Seems to work magnificently so far (accessing settings which seem very neat)
I have a feeling I am going to be in tears trying to work out why it doesn’t work for me on Cyberfox lol.
– Looks like a cyberfox thing here. it works well in firefox/chrome. I dont think it is officially suported for cyberfox
– Not sure setting window cannot be resized. As it opens in a new tab.
– Not reproducible in firefox/chrome.
– Dashboard can be accessed via Extension popup. Just click on the version number at the top.
All these new ads/traffic blocking extensions have been popping up everywhere trying to replace adblockplus, but none are really doing anything new. At least compare to abp on firefox.
If you wanted to, you can block third-party scripts with a simple rule in abp like this:
^$third-party,script
uBlock is nice and it probably work more efficiently than abp on chrome. But at the end of the day, uBlock is still subscribing to EasyList/Privacy and such. And those lists are maintained by people that use abp on firefox exclusively. There’s absolutely no better tool than abp on firefox to make and maintain blocking rules.
> If you wanted to, you can block third-party scripts with a simple rule in abp like this: ^$third-party,script […] There’s absolutely no better tool than abp on firefox to make and maintain blocking rules
It’s done through a point-and-click mini-matrix in uBlock.
And through the same point-and-click mini-matrix, one could just as easily create an exception for the current site, which would have to be something resembling “^$third-party,script,domain=~example.com”. And that’s an exception for one site — imagine wanting to add more exceptions, i.e. “^$third-party,script,domain=~example.com|ghacks.com”. uBlock, it’s always a mere point-and-click.
To claim that having to learn ABP filter syntax and manually craft ABP filters using that syntax is better tool to “make and maintain blocking rules” than merely pointing and clicking, I find this baffling.
> I’m didn’t claim that, you did
Alright, I read too much into “absolutely no better tool than abp on firefox to make and maintain blocking rules”.
“To claim that having to learn ABP filter syntax and manually craft ABP filters using that syntax is better tool to “make and maintain blocking rules” than merely pointing and clicking, I find this baffling.”
I’m didn’t claim that, you did. What I said is that, even uBlock is defaulting to EasyList/Privacy. Those list are maintained with abp on firefox. It is so mainly because of abp built-in live resources monitoring and rule creation tools. It makes the process of creating new rules pretty easy.
You on the other hand claim that people have to learn abp syntax rule to make it, but that untrue too. In abp on firefox, you can open the “blockable items” and see all the resources loaded of a page. You can click on any source that you wish to block and the process is pretty straight forward with pre-made rules and checkboxes for what you want the rule to do. You don’t have to learn the syntax at all if you don’t want to.
And to give an honest feedback, the dynamic blocking feature in uBlock is rather confusing to learn. The menu for the click boxes of the sources doesn’t have any label to be understandable. I have to dive in the the readme on github to learn about it. And I still don’t really understand what a ‘noop’ is. Compare to abp blockable item diablog, dynamic blocking is much more confusing for new users. And in the end, I find uBlock rule creation tools too confusing for even advance users.
I don’t doubt uBlock is a good blocker, and I prefer it over abp on Chrome when I do use Chrome. Though very seldom because Chrome has become a memory hog.
of course ublock works on the same principle as abp, but it uses less resources, while imho offering better features, plus it is open source. and reading the article it’s getting even more powerful. if those aren’t enough reasons for you to at least see some advantages, i don’t know what could be.
i recently switched and i can only say positive things about it.
I’m presently using uBlock 0.8.6.0, but from what I read here, the new All and 3rd-party requests filtering of version 0.8.7.0 (dev 8, but final release should appear within a few hours), I’m just about to move on to this new major release of uBlock. Major release because as I understand it, add-ons as AdBlockPlus/Edge and even Policeman will not have anything more to bring, or perhaps only an enhanced granular filtering in the case of Policeman. Looks like uBlock is about to become the all-in-one universal Web filter.
Pardon my ignorance but how do you install it? There is no installer that I can see.
Sorry found it.
https://github.com/gorhill/uBlock#installation