
Twitter algorithm goes public: Here is how it works


Twitter is a powerful tool for sharing ideas and connecting with people around the world. However, standing out on this platform can be challenging, particularly if you're looking to grow your following.
That's where the Twitter algorithm comes in. The algorithm is responsible for determining which tweets are shown to users and in what order, based on various factors.
The recent news of Twitter open-sourcing its algorithm has caused quite a stir in the tech industry. This makes it the first company to fully upload its algorithm to GitHub, providing tech enthusiasts with an exciting opportunity to delve deeper into the workings of the algorithm.
If you would like to take a look at the social media giant's algorithm, use this link to access the GitHub page on the Twitter algorithm.
Below you can see the tweet by Elon Musk announcing the publication of the Twitter algorithm on GitHub.
Twitter recommendation source code now available to all on GitHub https://t.co/9ozsyZANwa
— Elon Musk (@elonmusk) March 31, 2023
The three-step process
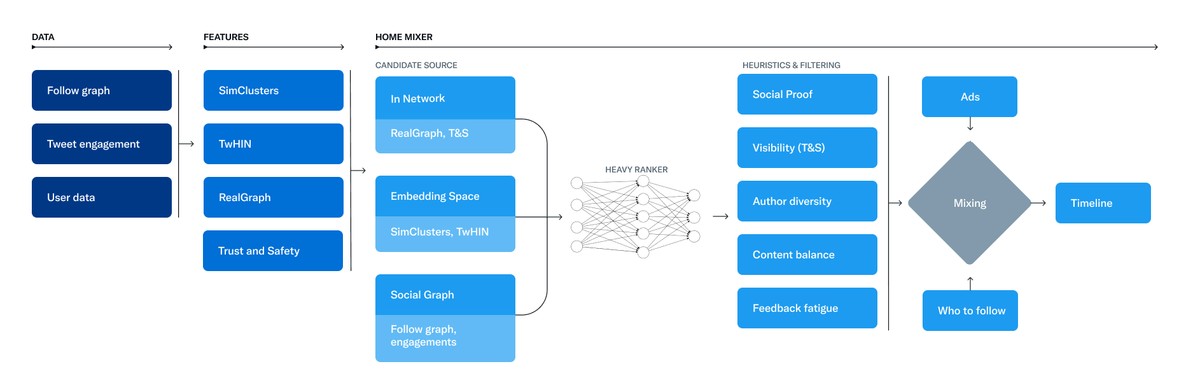
The Twitter algorithm is a three-step process consisting of data aggregation, feature formation, and mixing. In the data aggregation phase, the algorithm collects data about your followers, your tweets, and you. The data about your followers is straightforward, as it looks at who follows you. The data about your tweets is more complex, as it involves a linear ranking parameter that weighs several inputs about the tweet. The algorithm gives the biggest positive boost to "favCountParams," which unfortunately isn't defined in GitHub.
However, current thinking suggests that favCountParams is equivalent to Likes and Bookmarks, with each giving a 30x boost. Retweets give a 20x boost, while images or videos give a 2x boost. Surprisingly, a reply only gets a 1x boost.
In the next step, feature formation, the algorithm turns all the collected data into four key feature buckets:
- SimClusters
- TwHIN
- RealGraph
- Trust & Safety
SimClusters is the cluster where your tweet belongs, which is created algorithmically.
TwHIN estimates a user's probability of doing the target downstream tasks.
RealGraph takes information about the tweet, the tweet writer, and the potential tweet receiver to create a weighted graph to estimate the probability of any interaction.
Trust & Safety reads content to see if it violates Twitter's rules.
In the final step, mixing, the algorithm groups all of the features into three candidate sources: In Network, Embedding Space, and Social Graph, and then runs them through the Heavy Ranker.
The Heavy Ranker ranks every single tweet that could be shown to you based on the probability that it will lead to positive actions for Twitter.
After Heavy Ranker is calculated, several heuristics and filtering are applied to create a curated feed by creating content balance and author diversity.

Tips for ranking better on Twitter
If you want to optimize your tweets for the Twitter algorithm, here are some tips to keep in mind:
- Focus on Likes, then Retweets, and then Replies
- Post within your Cluster
- Avoid posting misinformation
- Use images and videos
- Pay for Blue
- Know your Follower Graph
- Avoid including links in your tweets
- Avoid using unknown language and typos











