
Find duplicate files and more with open source cross-platform tool Czkawka

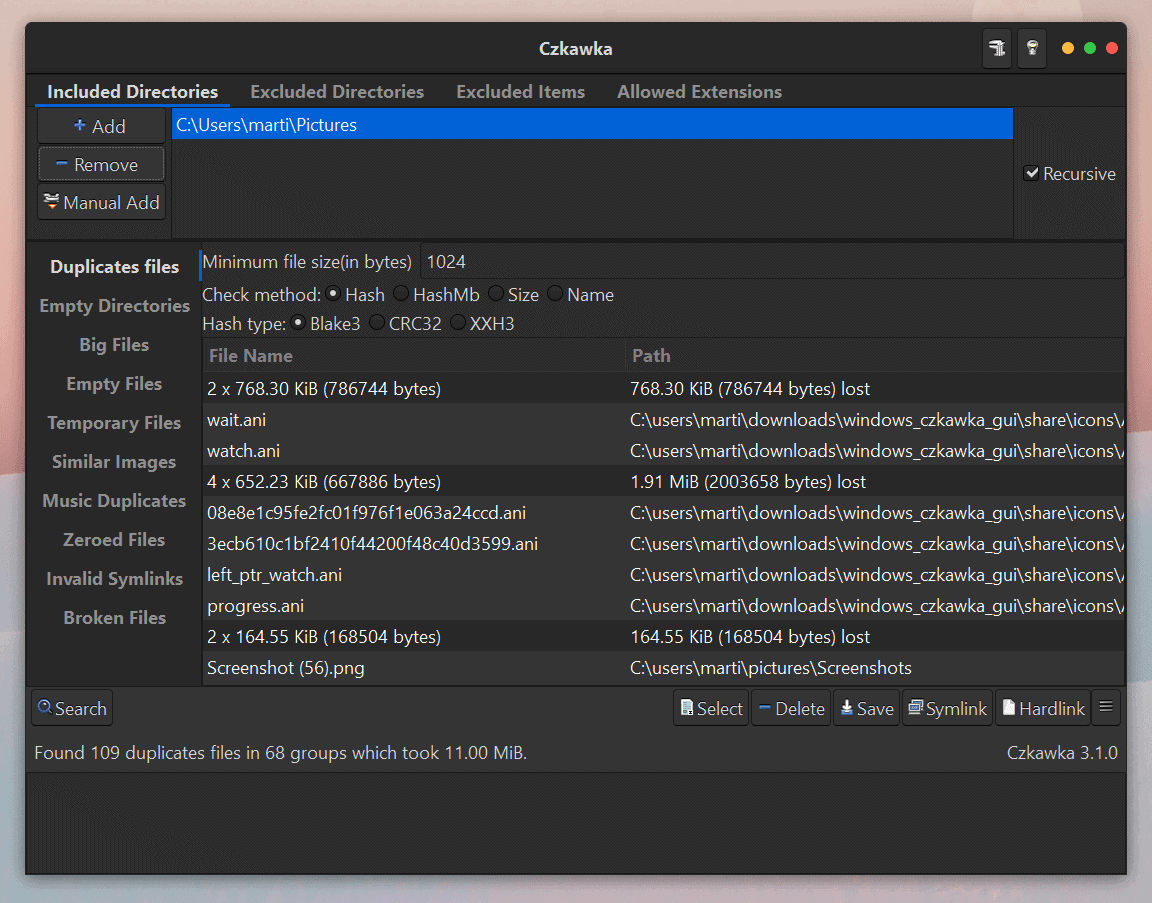
Czkawka is a free open source too to find duplicate images, broken files and more. It is written in Rust and available for Windows, Linux and Mac OS devices.
You may run the program right after you have downloaded it and extracted the archive it is supplied as. The main interface is separated into two areas: the directories and files selector at the top, and the function that you want to run on the selection at the bottom.
The program supports adding directories using a file browser or manual adds; you may also exclude directories and items or change the list of allowed file extensions.
The following operations are supported by Czkawka:
- Find duplicate files -- searches for dupes based on file name, size, hash or first Megabyte hash.
- Empty folders -- finds folders without content.
- Big files -- displays the biggest files, by default the top 50 biggest files.
- Empty files -- finds empty files, similarly to empty folders.
- Temporary files -- finds temporary files with certain file extensions.
- Similar images -- finds images which are not exactly the same, e.g. images with different resolutions.
- Zeroed files -- finds files that are zeroed.
- Same music -- finds music from the same artist, album and other search parameters.
- Invalid symbolic links -- finds symbolic links that point to files or directories that are missing.
- Broken files -- finds files with invalid extensions and files that are corrupted.
Some file search operations display search parameters at the top. The similar images search, for instance, accepts a minimum file size and a parameter that defines how similar images need to be to be detected.
Just hit the search button in the interface to run the task on the selected folders and files. Search was quick during tests, even on an not-so-powerful Surface Go device from Microsoft.
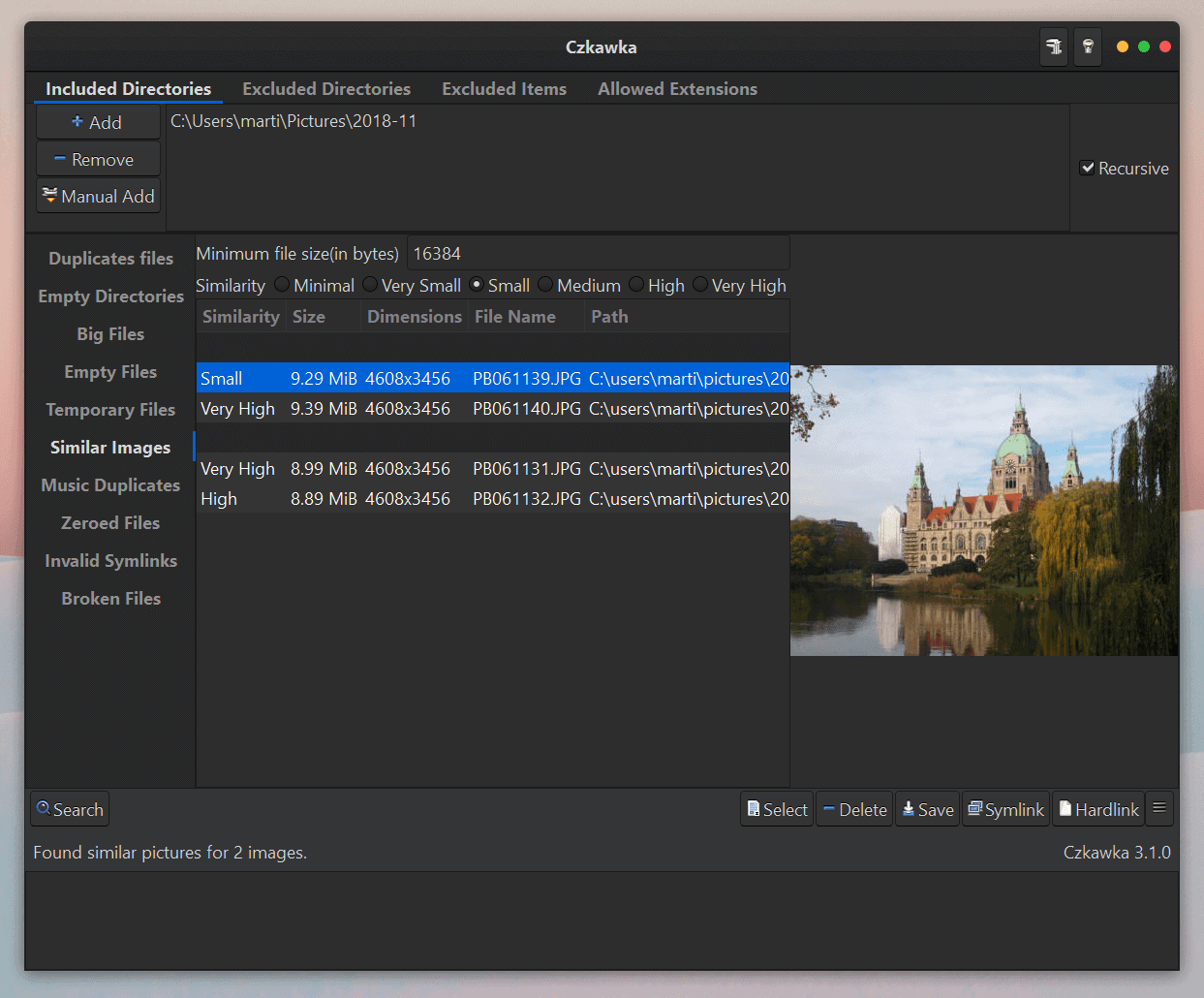

Files and folders that are found during the scan may be deleted right away, but there are also other options. For dupes, options are provided to save the selection, and to create symbolic or hardlinks. The symbolic links option sets the first file as the default and creates symbolic links from the other locations to it.
One thing that is missing, at least when it comes to the duplicate file finder, is the ability to preview certain file types right away in the interface. The similar images finder has that option, as it displays a preview of the selected image right in the interface. For duplicate files, no such option exists and that means that you need to open the files manually for verification to find out if they are indeed duplicates.
Some file types can be opened with a double-click on them.
Czkawka has a CLI version as well which is much smaller in size than the graphical user interface version. To get started, type czkawka_cli to get a list of supported commands and examples. Additional information on the CLI versino and general tips and tricks on using the program can be found on the developer's GitHub website.
Closing Words
Czkawka is an open source cross-platform to run file operations, such as finding duplicate files or similar images, on the selection. It is easy to use and quite fast when it comes to the execution of its operations.
Now You: do you use a program to find duplicates or run other file operations?















It doesn’t seem to give you the location of the files. If you can’t go and inspect them, how do you make use of this?
@Martin Brinkmann:
Did the Ghacks website just change its character encoding or restrict its supported character set? With the advent of much broader Unicode support in websites generally, I’ve been using typographical ellipses (dot dot dot), em dashes (long dashes), and en dashes (medium, number-range dashes) in online comments for a while now. As of this morning, my ellipses are showing up as … on Ghacks. Am I going to have to go back to ASCII on Ghacks?
I’m not aware of any changes, but will ask the dev team if they made any.
@Martin: I came across another comment in Ghacks from someone else, where a curly apostrophe and curly quotes had been replaced by similar “dummy characters.” (Sorry; I don’t remember which article.) I get the same result in Brave as in Pale Moon, and I haven’t changed anything to do with character encoding and fonts in either browser, or on my computer for that matter.
@Martin,
As @Peterc pointed out, there seems to be a glitch on the Ghacks website.
Even Comments other past topics, Special characters have been replaced with “?” or “— and so on.
And also here,
https://www.ghacks.net/2021/05/28/find-duplicate-files-and-more-with-open-source-cross-platform-tool-czkawka/#comment-4495836
@owl: Yes, I noticed that in one of your comments above, bullets (I’m assuming) had been replaced by question marks.
@Peterc,
Yes, you are right.
It’s a with a bullet “?” mark,
And a space is provided before and after the “|” mark to separate them.
My photo collection is enormous, over 1 million files (3 terabytes). It is “UltraSearch” that has shown unparalleled performance in organizing them (searching for duplicate files, renaming, moving, and deleting).
UltraSearch can search, extract, and edit all the files that exist locally, and has a file preview function that is very useful. It searches the Master File Table (MFT) on your hard disk directly, so there is no need for indexing, and it displays the search results clearly in just a few seconds.
Sorting and extraction is easy, and files can be opened directly or by specifying an external application such as an image editor.
UltraSearch: Find Your Files in Seconds | JAM Software GmbH
https://www.jam-software.com/ultrasearch_free
https://www.jam-software.com/ultrasearch_free/help.shtml
https://www.jam-software.com/company/terms_conditions.shtml
By the way, I have interested in this topic (article) so I tried “Czkawka”.
I was able to confirm that it is useful when searching for “duplicates” or “pseudo files” about a particular file, but it is too inefficient for organizing files as it cannot arbitrarily group or extract from enormous files and list them. In my experience, UltraSearch is the best.
@owl
UltraSearch seems to be good at what it does, but as near as I can tell it’s not an alternative to Czkawka, which is meant specifically for identifying duplicate files across a file system.
Am I missing something in the UltraSearch menus?
JAM Software has another product called TreeSize that specifically includes “duplicate finder” and “deduplication” features.
@todd-z,
Thanks for the reply.
As per your comment, UltraSearch is not a specialized application for duplicate file search function.
However, my comment is not a kind of “hypothetical” fiction, it is my actual use case.
UltraSearch, like “Everything”, lists all the files and folders in my system. That’s why I can identify “duplicate files” as a result.
In my use case, handling “duplicate files” was a source of concern, so in the past, I have tried various countermeasures and methods (such as using applications) to handle the duplicate files that occurred.
The point of arrival is “UltraSearch”.
I have already described my specific case study, so please give it a try, and you will see that you can easily find duplicate files with the application of UltraSearch.
Also, the “TreeSize” that you mentioned does not help in my use case.
https://www.jam-software.com/treesize_free
I am also using “WizTree” which is similar to TreeSize.
https://wiztreefree.com/
Final review about Czkawka:.
Differences between “UltraSearch”, which I use regularly, and “Czkawka” (actually, my personal opinion after trying it)
Czkawka is
Duplicate Finder by hash (Very High) is extremely reliable with “almost 100%” match rate. Therefore, it is very useful for search of “Similar Images”.
The disadvantages of Czkawka compared to UltraSearch are
The search keys (columns) are limited, and arbitrary search items cannot be added, which is inconvenient.
It is impossible to reorder the search results, so it is extremely inconvenient to organize the search results into any order or group.
Deletion cannot be selected to be moved to the “Recycle Bin”, so if execute a deletion, it will be a “complete deletion”, and if delete the wrong file, it will be unrecoverable, so have to be very careful when executing it.
I do a “hash search” of 1 million files (3 terabytes) at Very High, it will take about 7 hours to find the results. With UltraSearch, the search results for 1 million files (3 terabytes) are displayed in a few seconds.
The file preview function is limited to the use of “Similar Images” and Moreover the display area of the viewer cannot be variable.
File preview is not available outside “Similar Images”, so I have to reopen the file in another external viewer or app (this way it is difficult to compare and verify).
Conclusion.
Czkawka is useful for search of Empty Files, Empty Directories, Zeroed Files, Invalid Symlinks and Broken Files.
With Czkawka’s advanced “hash search” capability, I can do for search of “Similar Images”, which is hard to find with UltraSearch.
https://github.com/qarmin/czkawka/blob/master/instructions/Instruction.md
Czkawka is useful as a “complementary” feature to UltraSearch. I decided to use Czkawka in the future as well, depending on my needs.
PS
Czkawka’s search results do not explicitly stated the “Path”, so the location of each file is not known, and If I want to check the location of the file, use have to double-click on the file to open it. Very inefficient.
Postscript.
The “path” thing was explicitly shown by adjusting the column width.
The biggest drawback I found was that while running the hash search for “Similar Images” (until the results were displayed), if I ran any other program (even Notepad++), the system would freeze and become unresponsive. This is not a rare phenomenon; when multitasking programs, the PC will always freeze. In this case, even if I stop other programs (end task), the system will not normalize. If I don’t stop “hash search” or stop Czkawka, it will not normalize.
Since “hash search” in Czkawka takes a long time, Limitations on usage (don’t run multitask, wait until the search is finished).
System Specifications
Operating System: Windows 10 (x64) Version 2009 (build 19042.985)
Processor a: 3.00 gigahertz Intel Core i5-7400
256 kilobyte primary memory cache
1024 kilobyte secondary memory cache
6144 kilobyte tertiary memory cache
64-bit ready
Multi-core (4 total)
Memory Modules: 8102 Megabytes Usable Installed Memory
@GHacks, and Martin,
Martin’s article about “Czkawka”, so I recognized its usefulness, so I introduced it to the “free software introduction” portal site in Japan (freesoft-100.com), so that became an article.
https://freesoft-100.com/review/czkawka.html
https://freesoft-100.com/review/comment/20346/
I am looking forward to GHacks Tech News, which always provides timely and useful information.
Report and thank you to GHacks
@owl:
Are you using the free edition you linked to, or the paid, professional edition? It wasn’t clear to me from the documentation exactly what copying, moving, and deletion functions are unique to the professional edition. Also, I’m not getting any hits for “duplicat*” in the online manual, just a reference to deduplication in one of the UltraSearch product-summary pages. (Yeah, I know: I could always just download and install the free edition and muck around in it until I find what I’m looking for, but that takes … what’s the phrase I’m looking for? … time and effort. ;-)
BTW, I’m currently using the proprietary freeware program AllDup for duplicate-file-finding. It seems to work pretty well, but the user interface and work flow are more complex and confusing than in similar utilities I’ve seen.
@Peterc,
I am using the free version.
Functions such as copy, move, delete, etc. can be found in the contextual menu (right-click menu) or in the Ribbon menu “Operations” Tab.
Navigation: UltraSearch > Ribbon >
Operations Tab
https://manuals.jam-software.com/ultrasearch_free/EN/ribbonoperations.html
UltraSearch has an “intuitive” UI and icons, like Apple products, so I find it surprisingly easy to use. In addition, the FAQs and Online Manual are well-developed and easy to understand.
https://www.jam-software.com/ultrasearch_free/help.shtml
The basic usage can be understood in “Quickstart”.
Navigation: UltraSearch >
Quickstart
https://manuals.jam-software.com/ultrasearch_free/EN/?quickstart.html
Thanks, owl. I’ll have a look-see.
About my use case,
I have been taking pictures for more than 50 years, starting with film-based photography, and I have a lot of equipment (cameras, interchangeable lenses, filters, tripods, and other accessories) from those days. Since I started using digital cameras, I have been using a lot of such as exposure compensation (±) bracketing even due to their ease of use, so the number of frames I shoot is extraordinary.
One of the reasons I need a PC is to edit and manage my photos.
I used to use “Adobe Photoshop Lightroom”, but the amount of resources required to run the program was so large that the PC tended to overheat while in use, and eventually the motherboard and HDD deformed, and I lost my PC.
From this experience,
? Programs that run with less resource load and methods to use.
? Appropriate backup of data (images, etc.)
? PC heat removal measures
? Monitoring the temperature of the hardware (motherboard and HDD)
I learned the importance of
Those digital images are stored (copied) on multiple devices and are also uploaded to SpiderOakONE for “distributed management”.
When editing images, I create a separate folder for editing purposes and separate it from the original image storage location.
In some cases, I may create a tree-like folder, which may result in a number of “duplicate files”.
I’ve used Everything, WizFile, SearchMyFiles, and dupeGuru in the past to organize the large number of duplicate files left behind, but UltraSearch is finally fulfilling my purpose.
My use case with UltraSearch,
? Specify the devices to be searched (multiple devices can be processed at once)
? Set the filter to exclude filename extension from the search (for example, filename extension other than images).
? Define the items (columns) to be displayed.
Containing Path?|?Name???Size???Creation Date???Type
If you click on a column, it will sort by that column in ascending/descending order.
Columns can also be swapped, and items can be added or hidden.
Points to note,
UltraSearch requires a large amount of RAM when “executing the program,” and when UltraSearch is running (for several seconds), it will interfere with multitasking with other programs. In addition, the program may crash if you press any buttons, etc., before the search results in UltraSearch are displayed.
https://knowledgebase.jam-software.com/ultrasearch_professional/index4.shtml
Why does UltraSearch use so much memory (RAM)?
> For fast search results UltraSearch does not use an index but uses the working memory (RAM) to store the file information. Depending on the number of files and folders on your hard drive, this can be several hundred MB. In order to keep the amount of RAM required as small as possible, please select only the drives or folders you want to search in the drive list. If you deselect a drive, the file information for this drive will be deleted directly from the working memory.
In summary,
In my use case, there are numerous duplicate files, so “Ultra Search” is the best choice for efficient search and processing.
However, if that is not the case, and you want to search for duplicates or pseudo files in a specific file, Czkawka, which allows “hash search”, is useful.
In other words, I use different means (effective applications) depending on the issues I need to prioritize (objectives).
Revise the sentence
Incorrect: However, if that is not the case, and you want to search for duplicates or pseudo files in a specific file, Czkawka, which allows “hash search”, is useful.
Correct: However, if that is not the case, and you want to search for duplicates or pseudo files for a specific file, Czkawka, which allows “hash search”, is useful.
Regarding the name, it could be an issue for users who don’t speak Polish and who don’t use the program on a regular basis. My initial solution was to download the packages to a folder named “Czkawka [Hiccup]”. “Hiccup”, I’ll remember and find in an instant (in Windows, with Everything), but without the extra English-language keyword, trying to find the executable three months from now could turn out to be pretty czkawkaesque … I mean Kafkaesque. ;-)
PS: I “installed” Czkawka under my usual parent folder for “All Users” portable programs, and I appended “[Hiccup]” to the executables’ shortcuts. Czhkawkaesquicism averted.
“You may run the program right after you have downloaded it and extracted the archive it is supplied as.”
Does that mean it’s a portable program? I see from the documentation that its configuration and cache files are stored in the current user’s system profile (in Windows, roaming AppData), though.
Great program. It found some duplicated files which other duplicate programs couldn’t find.
Recommend it. A very nice, fast piece of free software. Its looks could be improved (talking about the Linux version). By the way, Czkawka should be pronounced ‘ch-cuff-ka’, ‘cuff’ as ‘cuff’ in ‘cufflinks’. I guess that the name is not the best way to promote the app. -“I’ve got a marvellous app. You should download it! It’s called… Let me say… Well… See you”.
Is it safe to delete zerod files and broken files.
Czkawka (polish) = hiccup.
I’ve been using this software for a month or so on an enormous photograph archive and found it, so far, to be quick and efficient in identifying duplicates and managing them.
Thumbs up from me !
“czkawka” is a polish word which translates to “hiccup” :)