Introducing DeepFloyd IF: From text to photorealistic images

Stability AI, in partnership with its AI research lab DeepFloyd, has released a new technology called DeepFloyd IF. This advanced text-to-image model is designed to generate high-quality images from text inputs.
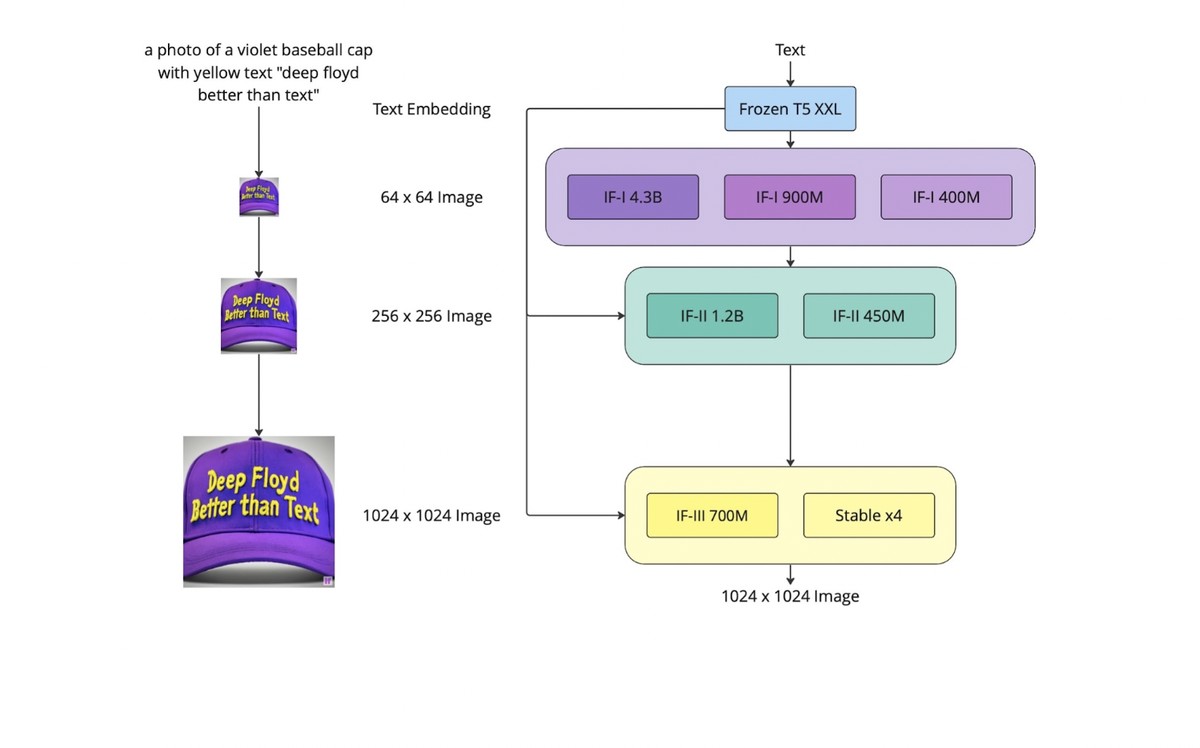
The DeepFloyd IF model uses the T5-XXL-1.1 language model as a text encoder to aid in understanding text prompts. Cross-attention layers are also employed to better align the text prompt and the generated image.
One of the most impressive features of DeepFloyd IF is its ability to accurately apply text descriptions to generate images with various objects appearing in different spatial relations, something that has been challenging for other text-to-image models.
Additionally, the model generates images with a high degree of photorealism, as reflected in its impressive zero-shot FID score of 6.66 on the COCO dataset. The model can also generate images with non-standard aspect ratios, including vertical or horizontal orientations and the standard square aspect.
DeepFloyd IF model's image-to-image translation
In addition to text-to-image generation, DeepFloyd IF offers zero-shot image-to-image translations. This is achieved by resizing the original image to 64 pixels, adding noise through forward diffusion, and using backward diffusion with a new prompt to denoise the image.
The style can be modified through super-resolution modules via a prompt text description. This approach allows for the modification of style, patterns, and details in the output image while maintaining the primary form of the source image without the need for fine-tuning.
Process for generating high-quality images
The DeepFloyd IF model works in three stages to generate high-quality images from text prompts. A frozen T5-XXL language model converts the text prompt into a qualitative representation in the first stage. Then, in the second stage, a base diffusion model is applied to transform the qualitative text into a 64×64 image, which is then upscaled to 256×256 using two text-conditional super-resolution models.
During the third stage of the process, a final model is used to enhance the image to a clear and high-quality 1024×1024 resolution. The IF model includes different versions of the base and super-resolution models, which have other parameters.
Although the third-stage model has yet to be available, alternative upscale models like the Stable Diffusion x4 Upscaler can be utilized.
Training dataset and licensing
DeepFloyd IF was trained on a high-quality custom dataset called LAION-A, which contains 1 billion (image, text) pairs. The dataset is an aesthetic subset of the English part of the LAION-5B dataset, and the data were filtered using custom filters to remove inappropriate content.
The model is initially released under a research license, and the creators welcome feedback to improve the model’s performance and scalability. The model can be used in various domains, such as art, design, storytelling, virtual reality, and accessibility.
The DeepFloyd IF model offers a promising advancement in the field of text-to-image generation. Its impressive capabilities and potential applications make it a valuable asset for researchers and professionals in various industries.
The model’s availability on a non-commercial, research-permissible license and the creators’ commitment to open-sourcing the model in the future aligns with Stability AI’s goal of sharing innovative technologies with the broader research community.
The creators welcome feedback and public discussions related to the model’s technical, academic, and ethical aspects, which can be accessed through the model’s weights, model card, and code available on GitHub, as well as through the Gradio demo provided for everyone.
Advertisement