Visual ChatGPT: Temporary solution until GPT-4's launch

Microsoft researchers have launched Visual ChatGPT, which aims to gather ChatGPT's and visual foundation models' abilities together to offer a better service before GPT-4.
ChatGPT launched a while ago and started a new era in the generative AI industry. More AI tools were produced following the fame and success of the chatbot. Microsoft has taken important steps to improve generative AI tools, especially in the past few years. Unfortunately, ChatGPT is a text-based language model, and it doesn't have the same abilities as DALL-E 2 or Wombo Dream. However, it has changed with the launch of Visual ChatGPT.
What is Visual ChatGPT?
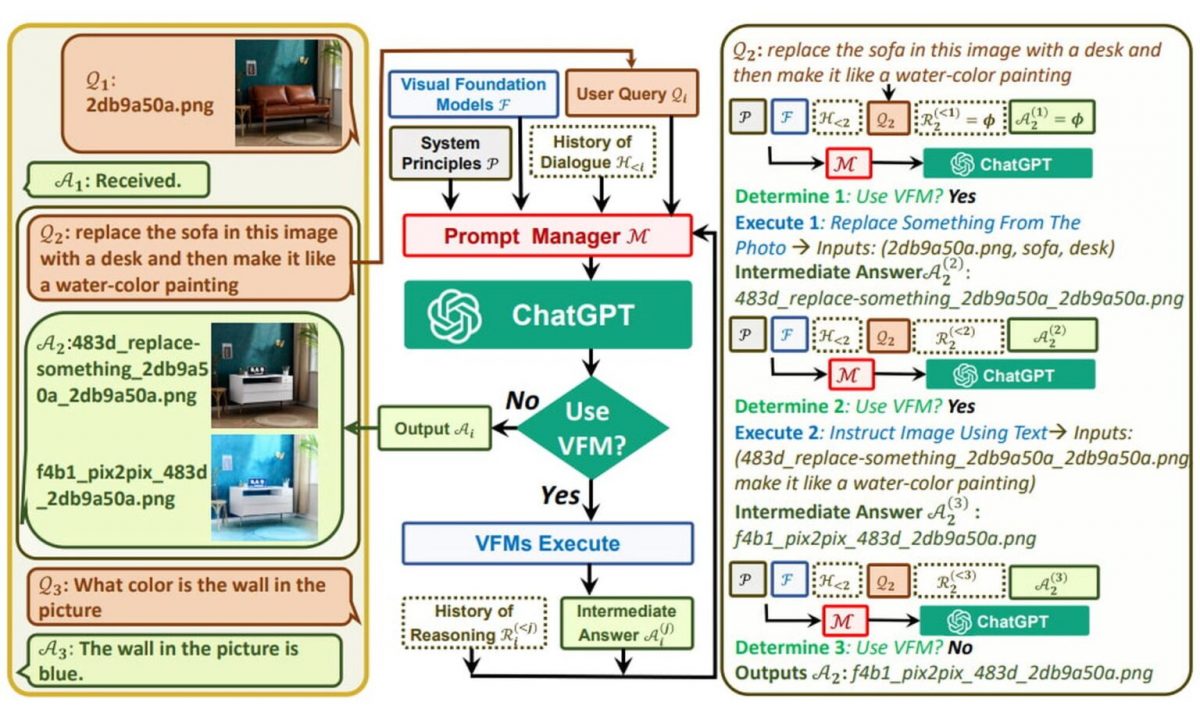
ChatGPT is a text-only chatbot that doesn't have the ability to generate images or videos, which is expected to change with GPT-4. However, Visual ChatGPT helps you generate, modify or crop an image. It mixes the powers of ChatGPT with other VFMs, such as Stable Diffusion, connecting ChatGPT and a series of Visual Foundation Models to enable sending and receiving images during chatting.
In other words, Visual ChatGPT helps users generate images out of text prompts. It lacked what other AI tools like Stable Diffusion had, and now, in a way, it is complete.
"Instead of training a new multi-modal ChatGPT from scratch, we build Visual ChatGPT directly based on ChatGPT and incorporate a variety of VFMs," says Microsoft.
GPU memory usage?
The researchers have also given the GPU memory usage stats on the official GitHub page. It requires high GPU and computation power. Below you will find the GPU memory usage of each visual foundation model:
| Foundation Model | Memory Usage (MB) |
|---|---|
| ImageEditing | 6667 |
| ImageCaption | 1755 |
| T2I | 6677 |
| canny2image | 5540 |
| line2image | 6679 |
| hed2image | 6679 |
| scribble2image | 6679 |
| pose2image | 6681 |
| BLIPVQA | 2709 |
| seg2image | 5540 |
| depth2image | 6677 |
| normal2image | 3974 |
| InstructPix2Pix | 2795 |
Capabilities
As mentioned, ChatGPT was trained to give users text-based answers but lacked image or video creation. Visual ChatGPT's capabilities are as follows:
- Send and Receive not only languages but also images.
- Provide complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps.
- Provide feedback and ask for corrected results.
GPT-4 release date
Last week, the CTO of Microsoft Germany announced that GPT-4 would be released "next week." He gave the statement on March 9, meaning the new model could launch in the upcoming days. OpenAI will at least introduce it to the community if it doesn't launch.
GPT-4 will be a multi-modal LLM that has the ability to create images and videos from text prompt on top of GPT-3.5's text prompt abilities. For more information about Visual ChatGPT, you can check the official Github page
Advertisement