Bulk Image Downloader 4.65 review

Most web browsers let you download individual images with relative ease. It usually takes only a couple of clicks to do so.
You will run into issues when you try to download multiple images displayed on a page, or pages. While it still works to select images individually for download, it takes a lot of time to do so. Time, that is better spend doing something else.
Bulk Image Downloader looks on first glance just like any other mass-downloader out there. But if you spend some time getting used to it, you will realize that it is probably the most sophisticated program in this niche that you can get you hands on.
Several features set the program apart, including its excellent parser and automation, but also the way multiple pages are crawled by the application, and options to use variables in addresses.
Bulk Image Downloader
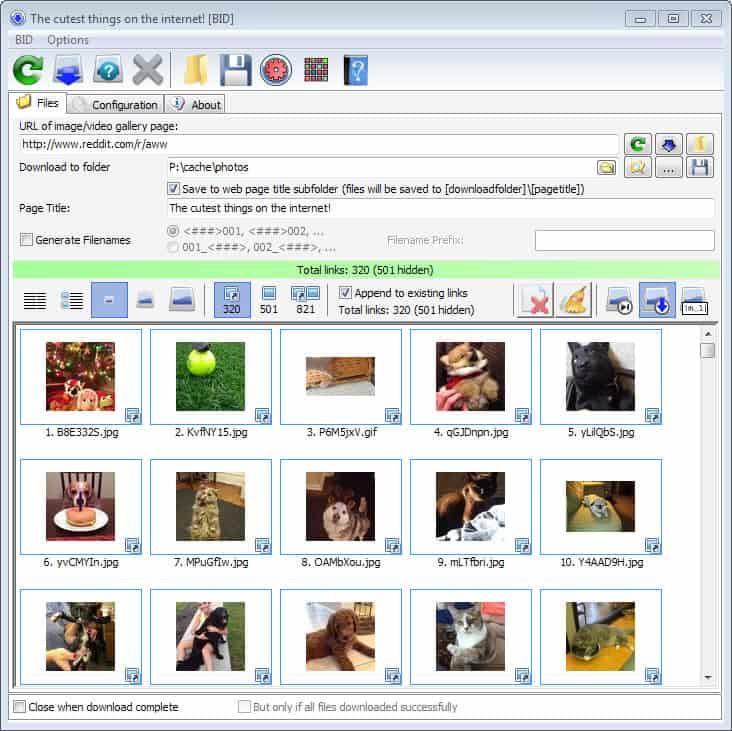
The installation of the program should not pose any troubles to you. The setup is clean and does not contain any third party offers.
Once done, you get the option to launch the main interface and a small drop box which you can use to drag and drop addresses on to.
Before you start to download your first batch of images. you may want to jump to the configuration. Important settings listed here include:
- The maximum number of pages per address that get downloaded (set to 20 by default). What this means is that if you select to download all images from reddit.com/r/aww/, Bulk Image Downloader will automatically parse the frontpage and the 19 pages that follow for images to add them to the download queue.
- Integration in Internet Explorer and Opera. Firefox users can use the BID extension for their browser, and Chrome users the browser extension for theirs.
- The maximum number of download threads (5 by default).
- Define a minimum or maximum file size for picture downloads.
You may also want to set the save directory in the main Bulk Image Downloader window to make sure images are saved into an appropriate location on your system.
Using the program
It could not be easier to use the Bulk Image Downloader application. All you have to do is add a web address to the program, either by dragging and dropping it on the drop box, or by adding it to the main interface directly.
The program starts to parse the url based on the selected configuration automatically. If things go well, you will soon see image thumbnails in the lower half of the screen indicating that images have been found that can be downloaded.
Above that, you find filtering options that you need to know about. BID will display full sized images only by default and download those once you give the command. This is usually the lowest number of images displayed in the filter toolbar. You can switch that to display all images found on a page, or only embedded pictures.
This means that smaller images, thumbnails for instance or icons, are not listed by default. This makes sense, as users may not want those when they download images from the Internet.
You can select items individually here for download, or hit the download button to download them all in rapid succession. The page title is used by default as the folder the images are stored in. You can change the title before you start the process if you like. It may make sense for example to add the address the images have been saved from to the folder information.
Existing images will be overwritten by default, which you can also change in the main interface. You can either have them skipped automatically, or renamed automatically so that they are saved and the existing image is preserved.
Tip: You can use the Queue Manager to add multiple addresses at once to the program that you want processed. It is alternatively possible to simply paste multiple urls into the main interface one after the other, as images that are discovered during the parsing stage are appended automatically to the queue by default. You will end up with them being saved into a single directory structure though.
Queue Manager
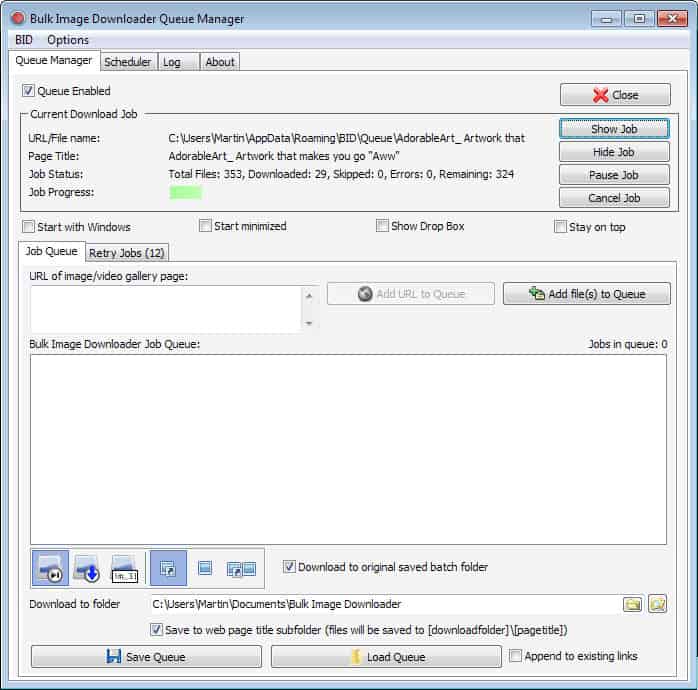
The Queue Manager displays all jobs that are currently being processed. One interesting feature of it is the ability to schedule jobs. If you want images to be downloaded during a specific time of the day, you can make that configuration here.
You can add urls to the queue manager directly, which is great for bulk importing them.
Selecting the download range manually
You can use variables to define the download range manually. This usually requires that you understand the url structure of the website that you want to download images from. If it uses a sequential structure, e.g. page/1/, page/2/, page /100/, then you can define the range easily using the following syntax:
http://www.example.com/page/[1-10]
This will parse page 1 to page 10 of the address. Pages that do not exist will be skipped automatically. I would advise you to select a range that is not too large, as you may run into slow downs if you select to parse 100 pages and download images from them, especially if those pages contain hundreds of images each.
What is interesting about this is that it will override the page limit that you have set in the application. If you select to download images from 30 pages, Bulk Image Downloader will do so.
That's however not the only option that you have here. You can also make use of advanced range specifiers:
- example.com/gallery/page[1,s-10].html - Will skip the first page, and download images from all pages up to page 10 (the s means skip)
- example.com/album[1-10,A]/pics[A]_[001-100].jpg - Uses the label A defined in [1-10,A] for identification of pictures as well.
There are a couple of other features that you may like. You can use it to download files from password protected websites for example (sites that require authorization), have the program load cookies automatically for that very same purpose (from a selected web browser), or use the integrated Link Explore to pick download links from a list of links discovered.
Bulk Image Downloader 5 update
Bulk Image Downloader 5 is a major upgrade of the application. The new version introduced several new features and options to the application which all of its users will benefit from.
This includes, among many other options better support for popular websites such as Facebook, Pinterest, or Flickr, support for Windows 10, better memory handling, and improved cookies handling.
You can read our full review of Bulk Image Downloader 5 here.
Verdict
Bulk Image Downloader is getting better with every release. This is the program to have if you are downloading images regularly on the Internet. It works with the majority of sites out there, including Facebook, Flickr, Reddit, Imgur, and many others, is highly flexible thanks to its advanced syntax, and does most of the work for you without you even realizing it.


















Once again A detailed write up that:
1 Fails to provide a download link
2 Fails to accurately describe this product, viz “trial software”; who would ever pay for SW they have not been able to trial?
3 Persists in avoiding mentioning the actual price for a full version.
Martin you may know a few things about computers but I’d suggest you re-evaluate your SW review process.
Peter, the link to the product website is listed in the article. I never link directly to downloads.
I agree that the review does not list the differences between trial and paid. Since this is a commercial program, I did not think it was necessary to do. The trial that you can download is limited in the number of images you can download per batch, and limits download speed somewhat.
I barely ever mention the price as it may change without notice. It is easy enough usually to find out on the developer site.
This works too
http://www.neodownloader.com/full-vs-lite/
I just dld Extreme Picture Finder and it did absolutely NOTHING. not surprised had my doubts from the beginning. I’ve tried many images download managers over the years and not a single one works the way its supposed to. 9 times out of 10 the program downloads the thumbnail image rather than the linked image that the thumbnail represents. so instead of getting the large 2650×4521 image I get the 300×300 thumnail image. Since then ive become a Master at Alt+S, Save As, Alt+W, and onto the next tab. I can get probably about a thousand images an our this way.
We need to download thousands of images at a time. I can assure you that, if used correctly, Extreme Picture Finder will work on all standard images. Go to the forum and ask for Maxim if you want individual help. We did and we have saved hundreds of man-hours as a result.
I save images by right-click save. Winning this software will save me heaps of time. Thanks for the opportunity to win such a great software. Please count me in the raffle thanks.
WOW! I won a license!! Thanks BID AND Martin/Ghacks! Really really will come in handy! This is a god send tbh!
Right click and save or I use IDM grabber to capture all the images on the page. However using IDM grabber can be somewhat of a pain.
I use webripper, despite the logo. Free can’t complain too much.
There are a number of programs/extensions I use to download images.
– Software
HTTrack is useful for ftp drives, or taking a copy of the whole website, but I must say I have used it less since I worked out the regular expression save options in DownThemAll
Zark’s TumblRipper is perfect for download of full Tumblr blogs.
– Firefox extensions
I mainly use DownThemAll to download images, though I combine it with one of two gallery extensions, especially when proceeding/following images have serial names (such as 001.ext, 002.ext)
FlashGot is quite useful for building a gallery of images, which can then be saved using DownThemAll. It also world for video and other files.
Alternatively Firefusk allows for quick galleries to be compiled, with a +/- serial image viewing option.
When there are multiple links to images I want to review prior to saving, I combine the Multi Links extension with the Bazzacuda Image Saver Plus extension to first open multiple tabs (with 1 image per tab) then to save all images in tabs.
For images on image hosting sites I use the extension Image Host Grabber.
Nevertheless, I have used Bulk Image Downloader on occasion, since it’s first iteration, and have been eagerly waiting the new version.
Another Right Clicker here
-BR
Hi Martin,
Thanks for this great giveaway.
I right-click and save, one image at a time.
Richard
Currently i am using Neo downloader . But now – a – days it is useless for me coz it unable to fetch google images . What i found this BID that really works with image and other website as well .
As others said, I use httrack, but would welcome the Bulk Image
downloader into my humble home… (:
I have used Teleport Pro for years. It works well, but it’s very top-heavy. You have to create “projects” and save configuration files, etc. BID sounds like a much more feasible way to download images on a whim. Thanks!
Down them all on Firefox for me.
I just wanted to write and tell you that Extreme Picture Finder is the best image downloader I’ve ever used. I like to read online comics and for years I’ve been looking for a program like this. But until now all I would find were programs that’d download a bunch of html objects, maybe some thumbnails, but never the full images I wanted. After trying well over 20 such programs over the years I still found the only way to download these pictures was to right click and save picture as, which was time-consuming to say the least. I didn’t have anymore hope for Extreme Picture Finder than I did for any other program I had used, and so I was shocked when it actually worked and downloaded specifically the images I was looking for. The options to download images hosted on another server, the in-program browser to login before downloading, and the web picture finder all help to make this a fantastic program. I’ll certainly be registering my program in a few days so I can use it. Thanks!
Right click -> Save or Ctrl-S…
When I download many images sometimes I use Free Download Manager, especially if their names follow some pattern, like sequential numbering.
Sometimes I use curl too, in a console window or invoked from batch files.
Thanks for the giveaway.
I use imagehost grabber addon for Firefox. It hasn’t been updated for 2 years now but it still works most of the time.
I wonder what kind of pictures you download ;)
(JPEG ones, I know, I know…)
I use right-lick —> save image and Firefox image download plugins most of the time. I wish I could win one license of Bulk Image Downloader software. It will definitely to save my time.
I just use right-click. A batch downloader sure would save me time!
Internet Explorer 10: |Right-click| + “Save picture as…”
clunky & tedious but works ok for getting just a couple of images
I’ve tried this software in the past and I didn’t like it very much, I can’t remember exactly what about it that I didn’t like (and I don’t care to) it probably had to do with the fiddly interface.
File Panther is the software I prefer, its a ‘simpler’ file downloader that just downloads files without needing too much fiddling around. Although, Bulk Image Downloader is certainly a good alternative for when you require a more indepth image search out of your file downloader.
Hi Martin and happy hols to you and all ghacks community.
I down pics either right clicking and saving if it’s just a few or with the software I won last year on the site :)
In chrome I use a extension called ¨Image Downloader¨ but only works in a simple page. Is good for daily use.
I try with other programs like ¨Neodownloader¨ but this fail when try to download multiples images galleries form some blogs o photo stock pages.
And for Tumblr have ¨TumblOne¨ is really simpe and fast. But only works on Tumblr pages of course.
Never find the ultimate image downloader software.
Yesterday I failed using dTa and FlashGot before finding this Firefox extension, BatchDownload: https://addons.mozilla.org/en-US/firefox/addon/batchdownload-10837
I used it to grab all the images on a webcomic’s server so I can catch up offline.
Yo, I’d like to take part in the giveaway. Currently using right click save as :P
I’d like such a program or neodownloader!
This program looks easy to use. I still use right click. Other browser extensions are either too confusing or they just save the thumbnail, not the original picture size. That’s been my experience, anyway. :)
If I just need to save a couple of pics, I’ll just right click and Save Picture. If I need to download many pics, I usually copy the main URL (and sometimes need to use a program URLGen to generate similar URLs) to JDownloader. Sometimes it work; sometimes it doesn’t. I know it’s very inconvenient, but that’s what I got atm.
ThumbsDown for Firefox
https://code.google.com/p/thumbsdown/
thanks for the contest
https://twitter.com/ha014/status/407537575725780993
Hi Martin,I was just trying to steal your images but Wget failed to do it
While this one works like a charm :
wget –user-agent=”Mozilla/5.0 (X11; Linux i686; rv:25.0) Gecko/20100101 Firefox/25.0″ -nd -r -l 1 -A gif,png,jpg,jpeg -e robots=off http://www.dedoimedo.com/computers/opensuse-13-1.html
Then when I replace address with https://www.ghacks.net/2013/12/02/bulk-image-downloader-4-65-review/ it doesn’t fetch anything.
How come?
ok, gotcha! little trick with cdn did the job :)
http://cdn.ghacks.net/2013/12/02/bulk-image-downloader-4-65-review/ works like a charm :)
Ah, the CDN, right ;)
I have no idea to be honest. Maybe it is a server setting or plugin that is preventing that? None comes to mind though.
This is a live saver. I download images one by one.
I snap the firefox window to the the left of my screen and then I snap a folder to the right of my screen,then I drag each picture from firefox to the folder.
Manually… and I’m getting really tired of the cut-and-paste merry-go-round.
Hello martin, previously i used to right click and save to download bulk images, but later i subscribed to a photos blog where i get interesting images on a topic…on that blog every single page contents lots of image…thats why downloading them all at once became pain for me..i search the net and found this program.. it provides exactly what i need as a bulk image downloader…every thing in this program is awesome…i was using this program for coupol of days..but its trial got expired and i left image downloading from that blog from then.
I often use DownThemAll and sometimes just right click.
I too, use right click and save, need a better way. This sounds like one.
I am dependant on “Right-Click + Save”.
I enjoyed reading your Review above and wish to win a license. Thank you,
I use DownThemAll extension with Firefox but it’s not as good as Bulk.
Currently I use downthemall to download images
I switch from Chrome (my default browser) to Firefox and use the “Save Images” extension.
Although Chrome is my default browser, I use Firefox with ‘Save Images’ add-on for downloading images. To me, this is one of the best add-ons of FF.
For example, if you have quite a few images embedded at one of your emails, you don’t have to individually select or if the images go across number of tabs (same tab using FastestFox or at left or right tabs), it can easily download all of them. Wonder why we don’t have it in Chrome in the same way as implemented in FF.
Everyone individually or occasionally Httrack. This sounds like a great improvement.
I download images by right-clicking them in firefox, but I would really like to try this software out…
So, Count me in…
I tweeted this @ https://twitter.com/ecsjjgg/status/407473733486403584
Richt click save… ;( and when some site block that with js I have no solution…
I use ‘DownThemAll’ the mass downloader for Firefox
Firefox plug-ins
Linky and Downthemall with filters and autopager to have everything on one page.
Heavy on the system but it works.
i use jdownloader to download images.
I use right click and save. Inconvenient! I’d like a software like BID, thanks
Most the time I right click and save (Save As) to download an image. I may repeat the process for multiple images.
Some times I use alternate methods when downloading via the usual way is too inconvenient or otherwise not possible. In many of these cases, software to download in batch (like Orbit Downloader V2.8.20) is often used.
At the moment I use HTTrack configured to only look for images when downloading bulk images from a webpage, but it looks that this application is much more features and easier to use.
> For a chance to win one of the licenses, let us know how you download images currently.
Right-click and save, my friend. Right-click and save.
By right click and save image as