Bitdefender releases Rootkit Remover tool for Windows

Rootkits are usually harder to identify and remove than regular malware due to the way these programs integrate themselves on a computer system. It is probably thanks to Sony and the company's infamous music CD rootkit that a larger audience became aware of rootkits in general and how dangerous they are.
Two types of rootkit removers exist. First programs that run more or less on their own, Kaspersky's TDSSKiller is an example of that, and second programs that scan the system but leave the interpretation of results to the user, with Gmer 2.0 being an example of that.
The first group of programs is usually only efficient against a set of rootkits, while the second group may identify them all but it also prone to report false positives.
Bitdefender's Rootkit Remover falls into the first group of programs, as it identifies and deletes a set of known rootkits from Windows systems. The program is available for 32-bit and 64-bit editions of Windows and runs more or less on its own. At the time of writing, it is capable of detecting and removing the following rootkits:
Rootkit Remover deals easily with Mebroot, all TDL families (TDL/SST/Pihar), Mayachok, Mybios, Plite, XPaj, Whistler, Alipop, Cpd, Fengd, Fips, Guntior, MBR Locker, Mebratix, Niwa, Ponreb, Ramnit, Stoned, Yoddos, Yurn, Zegost and also cleans infections with Necurs (the last rootkit standing)
The company notes that new rootkit families are added to the program as they become known. Program use could not be easier. You download and start the program on a supported version of Windows to get started.
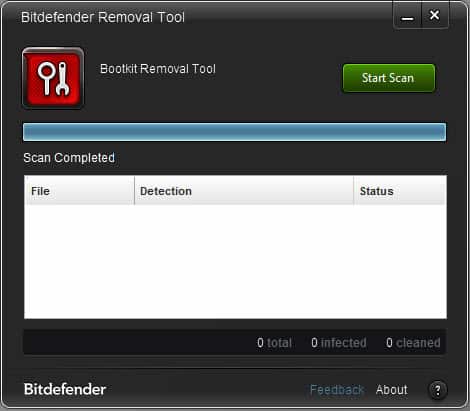
A click on start scan runs a scan on the system to detect any rootkit known by the software. The scan should not take longer than a couple of seconds before you are presented with notification that the removal process has been completed successfully.That's an irritating message on systems where no rootkit was detected on.
If a rootkit is found, you will be asked to restart the system now or later (with now being the best option) to clean the system from the infection.
Verdict
Bitdefender's Rootkit Removal Tool is a portable program for Windows to detect and remove several known rootkits and rootkit families from a system. It does not support automatic updates so that it is recommended to check the product homepage before you run scans to make sure you are running the latest version of the application.
The company should consider changing the status notification on clean systems to avoid consumer confusion.













You might want to try Malwarebytes Anti-Rootkit 1.01.0.1020 Beta available at http://downloads.malwarebytes.org/file/mbar
edit: I meant O/S [above] not C/S– sorry a typo
Martin, what exactly do you mean by “The program is available for 32-bit and 64-bit editions of Windows and runs more or less on its own.” ?
It is portable as well.
That it does not provide you with many options.
I was imagining a non-install application that would set data in Registry and/or application data folders …
loaded & ran OK, the 3sec scan seems more in-tune with a boot scan than a C/S drive
There is a Bootkit removal app
http://www.hotforsecurity.com/blog/new-bitdefender-tool-allows-bootkit-disinfection-1238.html
Maybe they have used the core code of the bootkit app as the core for the rootkit application. Well, it is certainly strange.
Tested the app. It froze on “preparing”
The download links on Bitdefender’s site (and your screenshot) are for BootkitRemoval and not for Rootkit Remover.
This may be a spelling mistake.
Bitdefender gives free copy of Bitdefender Internet Security 2013!
key : Q5YW7GP , 3NVQXKI
https://connect.bitdefender.com/pub/cc?_ri_=X0Gzc2X%3DWQpglLjHJlYQGtvbFtBF9WDwJNB8cP5lDzcrPzfKnB3WLqVXtpKX%3DACDA&_ei_=EpTFcrQnDaQnUBAPX-EWz51DdwFI7n0kc7egQfgOH7hs360pvMaBh8v6JO4S_3MfkmGSLg2vVQsNq8ZfY5aU4l2kVUp97b39
http://www.mirrorcreator.com/files/11KJONV4/bitdefender_isecurity.exe_links